
モデルの精度を向上させるにはどうするかというと、「学習するデータ量を増やす」か「特徴量を増やす」「パラメーターチューニングを行う」などの方法があります。
データ量はスクレイピングで取得する年数を増やすだけなので、今回は特徴量を増やす方法について紹介します。
この記事で紹介しているコードの改良版です。

現状の精度を把握する
まずは現状の精度を確認してみましょう。私の使用データは2020年~2023年の4年分になります
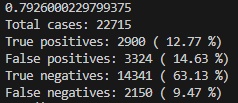
AUC:0.793
AUCはモデルの精度と考えていただいて大丈夫です。(正確には少し違いますが)
1に近ければ近いほど精度が高いと考えてください。
| 予測 | |||
| Positive | Negative | ||
| 正解 | Positive | TP 2900 (12.77%) | FN 2150 (9.47%) |
| Negative | FP 3324 (14.63%) | TN 14341 (63.13%) | |
そして表の見方ですが、
TP:3着以内と予想した馬が3着だった件数と確率(正解)
FN:3着以内と予想した馬が着外だった件数と確率(不正解)
FP:着外と予想した馬が3着以内だった件数と確率(不正解)
TN:着外と予想した馬が着外だった件数と確率(正解)
TPの値を上げていくことで予想の精度が上がったかどうかがわかるようになります。
モデルの作成のコードで出力するようにしてあるので、以下のような出力がターミナル上に出ているかと思います。
特徴量エンジニアリング
ではどうやって特徴量を増やせば良いのか?スクレイピングで取得する列やデータを増やすのも一つの手ですが、10年分取り直すのは時間が掛かって大変だと思います。
今あるデータを組み合わせて新たなデータを作ることで特徴量を増やしていきます。これが特徴量エンジニアリングです。
作成する特徴量はあくまでも例となります。組み合わせは無数にあるので、参考にしつつ効果のある特徴量を作成してみてください。
体重変化率
出走表に前走からの体重変化が表示されていると思います。486(+2)みたいなやつです。
単純な数値を見るのではなく、体重で割って変化率を出します。
計算式は簡単で、「体重変化÷体重」で算出できます。
コードは以下の通りです。
# 体重変化率を計算
for i in range(1, 6):
weight_dif = f"体重変化{i}"
weight = f"体重{i}"
df_combined[f"体重変化率{i}"] = df_combined[weight_dif] / df_combined[weight]
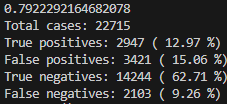
df_combined[f"体重変化率{i}"].replace([np.inf, -np.inf], np.nan, inplace=True) # 無限大やNaNをNaNに置換結果は以下のように出ました。TPは増えましたが、全体的に少し精度が下がってしまいました。
この特徴量の追加はやめます。
平均オッズ
過去5レース分の平均オッズを特徴量に入れることで、精度が上がるかを試してみます。
コードは以下の通りです。
# オッズに関連する列を数値に変換
odds_columns = ['オッズ1', 'オッズ2', 'オッズ3', 'オッズ4', 'オッズ5']
for col in odds_columns:
df_combined[col] = pd.to_numeric(df_combined[col], errors='coerce')
# 平均オッズを計算します。
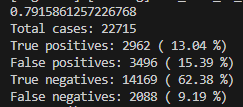
df_combined['平均オッズ'] = df_combined[odds_columns].mean(axis=1)結果は以下のように出ました。こちらもTPは増えましたが、全体的に少し精度が下がってしまいました。
オッズに引っ張られて正しく馬の強さを分析できていないのかもしれません。
この特徴量の追加はやめます。
平均斤量
過去5レース分の平均斤量を特徴量に入れることで、精度が上がるかを試してみます。
コードは以下の通りです。
# 斤量に関連する列を数値に
kinryo_columns = ['斤量', '斤量1', '斤量2', '斤量3', '斤量4','斤量5']
for col in kinryo_columns:
df_combined[col] = pd.to_numeric(df_combined[col], errors='coerce')
# 平均斤量を計算します。
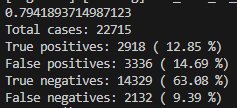
df_combined['平均斤量'] = df_combined[kinryo_columns].mean(axis=1)結果は以下のように出ました。AUCの値も上がり、間違いも減りました。このようにいくつも特徴量を考えてモデルの精度を測って確認していきます。
騎手の勝率
続いて騎手の勝率を算出してみます。競馬は騎手の実力が大きく結果を左右します。能力の低い馬でもジョッキーの腕で勝ってしまうこともあります。
コードは以下の通りです。
# 騎手の勝率
jockey_win_rate = df_combined.groupby('騎手')['着順'].apply(lambda x: (x==1).sum() / x.count()).reset_index()
jockey_win_rate.columns = ['騎手', '騎手の勝率']
jockey_win_rate.to_csv('calc_rate/jockey_win_rate.csv', index=False)
# '騎手'をキーにしてdf_combinedとjockey_win_rateをマージする
df_combined = pd.merge(df_combined, jockey_win_rate, on='騎手', how='left')騎手の勝率は実際の予想の際にも使うので、csvに出力しておきます。
レースデータをスクレイピングするコード「競馬AI⑥」のコードを修正する必要があります。
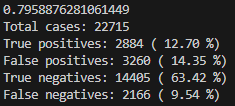
結果は以下のように出ました。AUCの値も上がり、間違いも減りました。
やはり騎手の勝率という特徴量は結果を左右するということがわかりました。
最終的なコード
特徴量エンジニアリングを入れたコードは以下の通りです。
import pandas as pd
from sklearn.preprocessing import LabelEncoder, StandardScaler
import numpy as np
import scipy.stats
import sys
def class_mapping(row):
mappings = {'障害':0, 'G1': 10, 'G2': 9, 'G3': 8, '(L)': 7, 'オープン': 7,'OP': 7, '3勝': 6, '1600': 6, '2勝': 5, '1000': 5, '1勝': 4, '500': 4, '新馬': 3, '未勝利': 1}
for key, value in mappings.items():
if key in row:
return value
return 0 # If no mapping is found, return 0
# データの読み込み
yearStart = 2020
yearEnd = 2023
yearList = np.arange(yearStart, yearEnd + 1, 1, int)
df = []
print("ファイル取得:開始")
for for_year in yearList:
var_path = "data/" + str(for_year) + "_new.csv"
var_data = pd.read_csv(
var_path,
encoding="SHIFT-JIS",
header=0,
parse_dates=['日付'],
date_parser=lambda x: pd.to_datetime(x, format='%Y年%m月%d日')
)
# '着順'カラムの値を数値に変換しようとして、エラーが発生する場合はNaNにする
var_data['着順'] = pd.to_numeric(var_data['着順'], errors='coerce')
# NaNの行を削除する
var_data = var_data.dropna(subset=['着順'])
# 必要であれば、'着順'カラムのデータ型を整数に変換する
var_data['着順'] = var_data['着順'].astype(int)
# "芝・ダート"が"芝"だけの行を選択
df.append(var_data[var_data['芝・ダート'] == '芝'])
print("ファイル取得:完了")
print("データ変換:開始")
# DataFrameの結合
df_combined = pd.concat(df, ignore_index=True)
# 既存のコード:走破時間を秒に変換
time_parts = df_combined['走破時間'].str.split(':', expand=True)
seconds = time_parts[0].astype(float) * 60 + time_parts[1].str.split('.', expand=True)[0].astype(float) + time_parts[1].str.split('.', expand=True)[1].astype(float) / 10
# 前方補完
seconds = seconds.fillna(method='ffill')
# 平均と標準偏差を計算
mean_seconds = seconds.mean()
std_seconds = seconds.std()
# 標準化を行う
df_combined['走破時間'] = -((seconds - mean_seconds) / std_seconds)
# 外れ値の処理:-3より小さい値は-3に、2.5より大きい値は2に変換
df_combined['走破時間'] = df_combined['走破時間'].apply(lambda x: -3 if x < -3 else (2 if x > 2.5 else x))
# 2回目の標準化の前に再度平均と標準偏差を計算
mean_seconds_2 = df_combined['走破時間'].mean()
std_seconds_2 = df_combined['走破時間'].std()
# 2回目の標準化
df_combined['走破時間'] = (df_combined['走破時間'] - mean_seconds_2) / std_seconds_2
print('1回目平均' + str(mean_seconds))
print('2回目平均' + str(mean_seconds_2))
print('1回目標準偏差' + str(std_seconds))
print('2回目標準偏差' + str(std_seconds_2))
# データを格納するDataFrameを作成
time_df = pd.DataFrame({
'Mean': [mean_seconds, mean_seconds_2],
'Standard Deviation': [std_seconds, std_seconds_2]
})
# indexに名前を付ける
time_df.index = ['First Time', 'Second Time']
# DataFrameをCSVファイルとして出力
time_df.to_csv('config/standard_deviation.csv')
#通過順の平均を出す
pas = df_combined['通過順'].str.split('-', expand=True)
df_combined['通過順'] = pas.astype(float).mean(axis=1)
# mapを使ったラベルの変換
df_combined['クラス'] = df_combined['クラス'].apply(class_mapping)
sex_mapping = {'牡':0, '牝': 1, 'セ': 2}
df_combined['性'] = df_combined['性'].map(sex_mapping)
shiba_mapping = {'芝': 0, 'ダ': 1, '障': 2}
df_combined['芝・ダート'] = df_combined['芝・ダート'].map(shiba_mapping)
mawari_mapping = {'右': 0, '左': 1, '芝': 2, '直': 2}
df_combined['回り'] = df_combined['回り'].map(mawari_mapping)
baba_mapping = {'良': 0, '稍': 1, '重': 2, '不': 3}
df_combined['馬場'] = df_combined['馬場'].map(baba_mapping)
tenki_mapping = {'晴': 0, '曇': 1, '小': 2, '雨': 3, '雪': 4}
df_combined['天気'] = df_combined['天気'].map(tenki_mapping)
print("データ変換:完了")
print("近5走取得:開始")
# '馬'と'日付'に基づいて降順にソート
df_combined.sort_values(by=['馬', '日付'], ascending=[True, False], inplace=True)
features = ['馬番', '騎手', '斤量', 'オッズ', '体重', '体重変化', '上がり', '通過順', '着順', '距離', 'クラス', '走破時間', '芝・ダート', '天気','馬場']
#斤量、周り
# 同じ馬の過去5レースの情報を新しいレース結果にマージ
for i in range(1, 6):
df_combined[f'日付{i}'] = df_combined.groupby('馬')['日付'].shift(-i)
for feature in features:
df_combined[f'{feature}{i}'] = df_combined.groupby('馬')[feature].shift(-i)
# 同じ馬のデータで欠損値を補完
for feature in features:
for i in range(1, 6):
df_combined[f'{feature}{i}'] = df_combined.groupby('馬')[f'{feature}{i}'].fillna(method='ffill')
# race_id と 馬 でグルーピングし、各特徴量の最新の値を取得
df_combined = df_combined.groupby(['race_id', '馬'], as_index=False).last()
# race_idでソート
df_combined.sort_values(by='race_id', ascending=False, inplace=True)
print("近5走取得:終了")
# '---' をNaNに置き換える
df_combined.replace('---', np.nan, inplace=True)
print("日付変換:開始")
#距離差と日付差を計算
# df_combined.insert(26, '距離差', df_combined['距離'] - df_combined['距離1'])
# df_combined.insert(27, '日付差', (df_combined['日付'] - df_combined['日付1']).dt.days)
# df_combined.insert(44, '距離差1', df_combined['距離1'] - df_combined['距離2'])
# df_combined.insert(45, '日付差1', (df_combined['日付1'] - df_combined['日付2']).dt.days)
# df_combined.insert(62, '距離差2', df_combined['距離2'] - df_combined['距離3'])
# df_combined.insert(63, '日付差2', (df_combined['日付2'] - df_combined['日付3']).dt.days)
# df_combined.insert(80, '距離差3', df_combined['距離3'] - df_combined['距離4'])
# df_combined.insert(81, '日付差3', (df_combined['日付3'] - df_combined['日付4']).dt.days)
# df_combined.insert(98, '距離差4', df_combined['距離4'] - df_combined['距離5'])
# df_combined.insert(99, '日付差4', (df_combined['日付4'] - df_combined['日付5']).dt.days)
#距離差と日付差を計算
df_combined = df_combined.assign(
距離差 = df_combined['距離'] - df_combined['距離1'],
日付差 = (df_combined['日付'] - df_combined['日付1']).dt.days,
距離差1 = df_combined['距離1'] - df_combined['距離2'],
日付差1 = (df_combined['日付1'] - df_combined['日付2']).dt.days,
距離差2 = df_combined['距離2'] - df_combined['距離3'],
日付差2 = (df_combined['日付2'] - df_combined['日付3']).dt.days,
距離差3 = df_combined['距離3'] - df_combined['距離4'],
日付差3 = (df_combined['日付3'] - df_combined['日付4']).dt.days,
距離差4 = df_combined['距離4'] - df_combined['距離5'],
日付差4 = (df_combined['日付4'] - df_combined['日付5']).dt.days
)
# 斤量に関連する列を数値に変換し、変換できないデータはNaNにします。
kinryo_columns = ['斤量', '斤量1', '斤量2', '斤量3', '斤量4','斤量5']
for col in kinryo_columns:
df_combined[col] = pd.to_numeric(df_combined[col], errors='coerce')
# 平均斤量を計算します。
df_combined['平均斤量'] = df_combined[kinryo_columns].mean(axis=1)
# 騎手の勝率
jockey_win_rate = df_combined.groupby('騎手')['着順'].apply(lambda x: (x==1).sum() / x.count()).reset_index()
jockey_win_rate.columns = ['騎手', '騎手の勝率']
jockey_win_rate.to_csv('calc_rate/jockey_win_rate.csv', index=False)
# '騎手'をキーにしてdf_combinedとjockey_win_rateをマージする
df_combined = pd.merge(df_combined, jockey_win_rate, on='騎手', how='left')
#日付
# 日付カラムから年、月、日を抽出
df_combined['year'] = df_combined['日付'].dt.year
df_combined['month'] = df_combined['日付'].dt.month
df_combined['day'] = df_combined['日付'].dt.day
# (年-yearStart)*365 + 月*30 + 日 を計算し新たな '日付'カラムを作成
df_combined['日付'] = (df_combined['year'] - yearStart) * 365 + df_combined['month'] * 30 + df_combined['day']
df_combined['year'] = df_combined['日付1'].dt.year
df_combined['month'] = df_combined['日付1'].dt.month
df_combined['day'] = df_combined['日付1'].dt.day
df_combined['日付1'] = (df_combined['year'] - yearStart) * 365 + df_combined['month'] * 30 + df_combined['day']
df_combined['year'] = df_combined['日付2'].dt.year
df_combined['month'] = df_combined['日付2'].dt.month
df_combined['day'] = df_combined['日付2'].dt.day
df_combined['日付2'] = (df_combined['year'] - yearStart) * 365 + df_combined['month'] * 30 + df_combined['day']
df_combined['year'] = df_combined['日付3'].dt.year
df_combined['month'] = df_combined['日付3'].dt.month
df_combined['day'] = df_combined['日付3'].dt.day
df_combined['日付3'] = (df_combined['year'] - yearStart) * 365 + df_combined['month'] * 30 + df_combined['day']
df_combined['year'] = df_combined['日付4'].dt.year
df_combined['month'] = df_combined['日付4'].dt.month
df_combined['day'] = df_combined['日付4'].dt.day
df_combined['日付4'] = (df_combined['year'] - yearStart) * 365 + df_combined['month'] * 30 + df_combined['day']
df_combined['year'] = df_combined['日付5'].dt.year
df_combined['month'] = df_combined['日付5'].dt.month
df_combined['day'] = df_combined['日付5'].dt.day
df_combined['日付5'] = (df_combined['year'] - yearStart) * 365 + df_combined['month'] * 30 + df_combined['day']
# 不要となった 'year', 'month', 'day' カラムを削除
df_combined.drop(['year', 'month', 'day'], axis=1, inplace=True)
print("日付変換:終了")
categorical_features = ['馬', '騎手', 'レース名', '開催', '場名', '騎手1', '騎手2', '騎手3', '騎手4', '騎手5'] # カテゴリカル変数の列名を指定してください
# ラベルエンコーディング
for i, feature in enumerate(categorical_features):
print(f"\rProcessing feature {i+1}/{len(categorical_features)}", end="")
le = LabelEncoder()
df_combined[feature] = le.fit_transform(df_combined[feature])
# エンコーディングとスケーリング後のデータを確認
print("ファイル出力:開始")
df_combined.to_csv('encoded/encoded_data.csv', index=False)
print("ファイル出力:終了")
まとめ
いかがでしたでしょうか?このように特徴量同士を組み合わせることで新たな特徴量を作り出し、精度を上げることが出来ます。
自分なりの特徴量を生み出し、より良いモデルを作成してみてください。
私も様々な特徴量を追加しモデルの精度を上げています。今回精度を下げている特徴量がわかったので、私のモデルも整理しなければなりませんね。
次はパラメーターチューニングについても紹介します。お楽しみにしていてください。



コメント
いつも楽しく読ませていただいています
「競馬AI⑥」のコードを修正する必要
とあるのですがどこを修正すればよいのでしょうか?
またpredict.pyを実行した結果の馬名が出ず数字になってしまいます
お暇なときでよいのでお返事いただければ幸いです
よろしくお願いします
コメントありがとうございます。
⑥のコードを修正しました。
308行目~315行目をご確認ください。
騎手の勝率を記録したcsvのデータをスクレイピング時に読み込み、新たな列として追加しています。
また、馬名はカタカナでは予測時にエラーになってしまうので数値に変換しています。
結果に馬名を含めたいのであれば、事前に馬名を退避しておいて、予測後にデータフレームに戻してあげれば良いです。
・エンコーディング前に退避(17行目あたりに追加)
uma = new_data[“馬”]
・予測後にデータフレームに戻す(86行目あたりに追加)
new_data[“馬”] = uma
ありがとうございます。
素人の質問に丁寧な解答 本当ににありがとうございます。
しっかりとコードを読まないといけないと痛感しました。
また、実際の買い目の参考に利用した結果、なかなか良い思いをさせてもらいました。
軸馬探しにはかなり有効だと思っています。
競馬AIの記事以外も楽しく読ませてもらってます。
これからも色々な楽しい記事をお願いします。
お世話になっております。
AUCの具体的な説明が知りたいです。
AUC「Area Under the Curve」は、機械学習における分類問題に使われる性能指標です。
今回の競馬AIの場合、3着以内に入る馬か、入らないかの2項分類を行っています。
AUCの値が1に近ければ近いほど、モデルは馬の成績を正確に予測できると考えられます。
機械学習の専門家というわけではないので、正確な解説は調べていただいた方が良いと思います。
いつも楽しく読ませていただいています。
特徴量として馬の複勝率を追加しました。(騎手の勝率を算出するコードを参考にしています。)
【encode.py】
# 複勝率
fukusho_rate = df_combined.groupby(‘馬’)[‘着順’].apply(lambda x: (x <= 3).sum() / x.count()).reset_index()
fukusho_rate.columns = ['馬', '複勝率']
fukusho_rate.to_csv('fukusho_rate_data/fukusho_rate_data.csv', index=False)
# '馬'をキーにしてdf_combinedとplacement_rateをマージする
df_combined = pd.merge(df_combined, fukusho_rate, on='馬', how='left')
【race_table_scraping.py】
# CSVファイルから複勝率データを読み込む
fukusho_rate_df = pd.read_csv('fukusho_rate_data/fukusho_rate_data.csv')
# 馬ごとの複勝率を取得して新たなデータフレームを作成
uma_fukushorate = fukusho_rate_df.groupby('馬')['複勝率'].first().reset_index()
# df_all_resultsとuma_fukushorateを結合するコード
df_all_results = df_all_results.merge(uma_fukushorate, on='馬', how='left')
すると、特徴量の重要度が下記のように極めて高く表示され、
1) 複勝率 433.000000
predict_resultの予測結果の値が異常な値になってしまいます。
(ある馬は0.9643…のように極めて高く、ある馬は0.0000…のように極めて低く出る)
複勝率はスタンダードな特徴量だと思いますが、追加は避けた方が良いのでしょうか?
それとも、このような場合、適切に処理する方法があるのでしょうか?
お手数をおかけし恐縮ですが、ご教示いただけますと幸いです。
コメントありがとうございます。
複勝率は私も追加していたことがありますが、同様に過剰に影響してしまい現在は特徴量から除外しています。
想像にはなってしまうのですが、複勝率は出走数が多くなればなるほど下がっていきます。
掲示板内の4,5着でも下がります。なので出走数が少ない方が有利になってしまい、そのままでは有効な特徴量と言えないかもしれません。
もし使うのであれば、出走数によって重みづけをし、出走数が多い馬が不利にならないような調整が必要なのかもしれません。
いつもお世話になっております。
初歩的な質問で恐縮ですが、こちらの記事で作成した特微量は【競馬AI⑥】で作成したレースデータ作成のコードにも反映されているようですが、例えばこちらのencode.pyで新しく私がオリジナルで作成した特徴量も反映しなければならないのでしょうか?
もし反映しなければならないのであれば、お手隙の際にその方法を教えていただけると幸いです。よろしくお願い致します。
コメントありがとうございます。
ご認識の通りです。
どのような特徴量を作られたかわかりませんが、新しく作成した特徴量はレースデータ側にも追加する必要があります。
学習データと予測データの特徴量(カラム名・カラム数)は一致していなければなりません。
反映方法ですが、基本的にencode.pyで作成した特徴量と同じ作り方で追加するという回答になってしまいます。
例えば、「近5走の平均オッズを計算して追加したのであれば、同じように計算して追加する」といったような。
参考になれば幸いです。
お世話になります。1点質問させてください
# 現象
eocode.py 22行目 var_data = pd.read_csv(
上記のCSV読み込み処理に関して、読み込み対象のCSV(例:data/2022.csv)の着順カラムに[中]や[除](競走中止、競争除外)が入っている場合があるかと思います
その場合
25 行目 dtype={0: str, 3: int, 7: int
にて、着順をint型として読み込む際に、[中]や[除]が入っているためエラーになってしまいます。
# 質問
CSV(例:data/2022.csv)を読み込む際、競争中止や競争除外のレコードは除外すればよいのでしょうか?
機械学習は初心者のため的外れな質問でしたら申し訳ありません
少し前のソースコードのままになっているようです。
競馬AI②の記事のコードを再度ご確認いただき、コードをアップデートしてみてください。
以下のように数値に変換できない着順を除外するようにしています。
# ‘着順’カラムの値を数値に変換しようとして、エラーが発生する場合はNaNにする
var_data[‘着順’] = pd.to_numeric(var_data[‘着順’], errors=’coerce’)
# NaNの行を削除する
var_data = var_data.dropna(subset=[‘着順’])
# 必要であれば、’着順’カラムのデータ型を整数に変換する
var_data[‘着順’] = var_data[‘着順’].astype(int)
興味深く拝読させていただいております。このような興味を持って読める記事を執筆してくださり、ありがとうございます。
ここで、一つ質問があり、投稿させていただきました。この記事7のエンコードなのですが、
ValueError: invalid literal for int() with base 10: ‘取’
などのエラーが出て、うまくいきません。一方で。2のエンコードはうまくいく状態です。
何か対処方法などありましたら、ご教示いただけますと幸いです。
コメントありがとうございます。
2のエンコードとコードの差分があったようです。
29~34行目に以下のコードを足して更新したので、試していただけますか?
# ‘着順’カラムの値を数値に変換しようとして、エラーが発生する場合はNaNにする
var_data[‘着順’] = pd.to_numeric(var_data[‘着順’], errors=’coerce’)
# NaNの行を削除する
var_data = var_data.dropna(subset=[‘着順’])
# 必要であれば、’着順’カラムのデータ型を整数に変換する
var_data[‘着順’] = var_data[‘着順’].astype(int)
丁寧なご返信、誠にありがとうございます。
先ほど更新後のコードを試してみましたら同様のエラーが発生いたしました。
また、前回は記していなかったのですが、
TypeError: Cannot cast array data from dtype(‘O’) to dtype(‘int64’) according to the rule ‘safe’
このようなエラーも発生しております。
お手数をおかけし申し訳ございません。
データの型を指定しているのがダメみたいですね。
25行目を削除し再度更新しました。
確認お願いします。
この修正で、無事に走り、終了することができました!
本当に感謝です。ありがとうございました。
良かったです。
記事が多く、バージョン管理が上手くできておらずご迷惑をおかけしました。
いつもお世話になっております。
今日予測結果を眺めていたところ、騎手の名前を知っているのに騎手の勝率の行の何人かの騎手の勝率が空欄で、不思議に思い成績を確認したところずっと騎乗しているが名前の表記が変わってしまっている騎手だとわかりました。例えばムルザバエフ騎手が今まではムルザバだったのが、ムルザに表記が代わっていたり、石川裕紀人騎手が、もともとは石川裕紀という表記だったりと、代わっている騎手が多数いました。彼ら騎手の勝率の特徴量が機能せず予測確率が高いということになっていました。そのような変化にはどのように対応すればよろしいでしょうか?
お手数ですが、アドバイスお願いします。よろしくお願いします。
私自身その変化に気づいていませんでした。
ありがとうございます。
対応するのであれば、calc_rateフォルダの「jockey_win_rate.csv」の対象の騎手の名称を修正してみてください。
自動で修正するのは難しいので手動での対応になります。
いつもお世話になっています。
特徴量に開催場ごとの勝率と右回り・左回り毎の勝率を追加しようと考えているのですが
コードとしては騎手の勝率のような書き方になりますでしょうか
開催場ごとの馬の勝率ですか?
以下のようなイメージになるのではないでしょうか?
# ‘場名’と’馬’ごとの勝率を計算
horse_win_rate = df_combined.groupby([‘場名’, ‘馬’])[‘着順’].apply(lambda x: (x == 1).sum() / x.count()).reset_index()
horse_win_rate.columns = [‘場名’, ‘馬’, ‘馬の勝率’]
コードありがとうございます。
実際に記載いただいたコードを追加し実行すると、ラベルエンコードの部分でKeyError: ‘場名’が表示されます。
categorical_featuresから’場名’を削除すると正常に動作するのですが、そうするとencoded_data.csv内の’場名’が変換されません。どこかに’場名’の追加必要だとは思うのですが何処に追加すればよいでしょうか?
勝率を計算した後に、元のデータフレームにマージすると思いますが、
そのマージで予期しないカラムまでマージしているのではないでしょうか?
データフレームのカラムを確認してみてください。
早急な回答ありがとうございます。原因がわかりました。
ご指摘のとおりデータフレームのマージ部分が原因でした。
ありがとうございました。
今回の騎手勝率は、予測時点では未来の勝率まで含まれているのでリークにならないでしょうか?
目的変数”着順”の特徴量を使用して、説明変数を作成する場合は当日を含まない直近の着順を加工して特徴量を作成するのがよいと考えたのですがいかがでしょうか。
当日や明日のレースを予測するので、この勝率には未来の勝率は含まれないと考えるのですが解釈間違っていますか?