
前回からの続きの記事になります。

今回は、前回加工したデータを学習させて着順予想するモデルを作成していきます。
ここは一旦完全にコピペのみで作成していただき、後からパラメータなどを変更していきながら最適なモデルを模索していきます。
早速コピペしていきましょう。
モデル学習コード
コード
以下のコードをコピペでファイルを作成してください。
import lightgbm as lgb
import pandas as pd
from sklearn.metrics import roc_curve,roc_auc_score
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
import numpy as np
def split_date(df, test_size):
sorted_id_list = df.sort_values('日付').index.unique()
train_id_list = sorted_id_list[:round(len(sorted_id_list) * (1-test_size))]
test_id_list = sorted_id_list[round(len(sorted_id_list) * (1-test_size)):]
train = df.loc[train_id_list]
test = df.loc[test_id_list]
return train, test
# データの読み込み
data = pd.read_csv('encoded/encoded_data.csv')
#着順を変換
data['着順'] = data['着順'].map(lambda x: 1 if x<4 else 0)
# 特徴量とターゲットの分割
train, test = split_date(data, 0.3)
X_train = train.drop(['着順','オッズ','人気','上がり','走破時間','通過順'], axis=1)
y_train = train['着順']
X_test = test.drop(['着順','オッズ','人気','上がり','走破時間','通過順'], axis=1)
y_test = test['着順']
# LightGBMデータセットの作成
train_data = lgb.Dataset(X_train, label=y_train)
valid_data = lgb.Dataset(X_test, label=y_test)
params={
'num_leaves':32,
'min_data_in_leaf':190,
'class_weight':'balanced',
'random_state':100
}
lgb_clf = lgb.LGBMClassifier(**params)
lgb_clf.fit(X_train, y_train)
y_pred_train = lgb_clf.predict_proba(X_train)[:,1]
y_pred = lgb_clf.predict_proba(X_test)[:,1]
#モデルの評価
#print(roc_auc_score(y_train,y_pred_train))
print(roc_auc_score(y_test,y_pred))
total_cases = len(y_test) # テストデータの総数
TP = (y_test == 1) & (y_pred >= 0.5) # True positives
FP = (y_test == 0) & (y_pred >= 0.5) # False positives
TN = (y_test == 0) & (y_pred < 0.5) # True negatives
FN = (y_test == 1) & (y_pred < 0.5) # False negatives
TP_count = sum(TP)
FP_count = sum(FP)
TN_count = sum(TN)
FN_count = sum(FN)
accuracy_TP = TP_count / total_cases * 100
misclassification_rate_FP = FP_count / total_cases * 100
accuracy_TN = TN_count / total_cases * 100
misclassification_rate_FN = FN_count / total_cases * 100
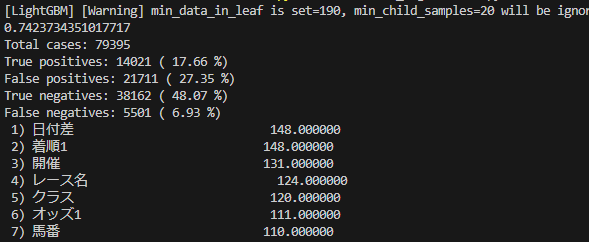
print("Total cases:", total_cases)
print("True positives:", TP_count, "(", "{:.2f}".format(accuracy_TP), "%)")
print("False positives:", FP_count, "(", "{:.2f}".format(misclassification_rate_FP), "%)")
print("True negatives:", TN_count, "(", "{:.2f}".format(accuracy_TN), "%)")
print("False negatives:", FN_count, "(", "{:.2f}".format(misclassification_rate_FN), "%)")
# True Positives (TP): 実際に1で、予測も1だったもの
# False Positives (FP): 実際は0だが、予測では1だったもの
# True Negatives (TN): 実際に0で、予測も0だったもの
# False Negatives (FN): 実際は1だが、予測では0だったもの
# モデルの保存
lgb_clf.booster_.save_model('model/model.txt')
# 特徴量の重要度を取得
importance = lgb_clf.feature_importances_
# 特徴量の名前を取得
feature_names = X_train.columns
# 特徴量の重要度を降順にソート
indices = np.argsort(importance)[::-1]
# 特徴量の重要度を降順に表示
for f in range(X_train.shape[1]):
print("%2d) %-*s %f" % (f + 1, 30, feature_names[indices[f]], importance[indices[f]]))※2023/7/11更新
①モデル学習時の除外項目追加
②モデルの評価をAUCに変更
③正解率、特徴量の重要度などの確認出力を追加
※着順を除外している理由
競馬の着順予想は、様々なデータからどの馬が速いのかを予測します。着順はあくまでもそのレースの結果であって、速さを表す指標ではありません。
レースに出ていない馬との関係性はないのに、速いと誤解させてしまいます。
例えばG1で連続で2桁着順の馬と未勝利戦や1勝クラスで連続で2~3位を取っている馬を比べた場合に、未勝利戦を走っている馬の方が速いと判断されてしまうようなイメージです。
※人気・オッズを除外している理由
単純に人気・オッズの影響が大きすぎて、ほぼ1~5番人気までしか上位予想されなかったため
※上がり、走破時間、通過順を除外している理由
この3つのデータは実際のレース予測時には、使えないデータのため除外(出走前なので空で予測されてしまう)
実行
※実行前に「model」フォルダの作成をお忘れなく!
実行するには以下のコマンドをターミナルで打ち込んでください。
python estimation.py実行すると「model」フォルダにファイルが作成されているはずです。
結果の確認
実行するとターミナルに以下のような結果が出力されます。
0.7423734…と表示されている値が大きければ大きいほどモデルの精度が良いということになります。
約8万頭の馬の順位を予測して、3着以内と予測して3着以内だったものが17.66%、3着以内と予測して4着以下だったものが27.35%だったという意味になります。
モデルの改善
モデルを改善するには2つの方法があります。
- 学習データの追加
- ハイパーパラメータの修正
学習データの追加
スクレイピングでは取得できるデータをほとんど取得できているので、直近5走のデータの追加が考えられます。
コース、斤量、人気などは使っていません。
スクレイピングで取得していない払い戻し額なども使えるかもしれません。
パラメータの修正
パラメータは以下の部分です。
params={
'num_leaves':32,
'min_data_in_leaf':190,
'class_weight':'balanced',
'random_state':100
}パラメータを変えながら最大値を目指してみてください。
LightGBMについて
モデルを改善するにしても、ここから先は専門的な知識が必要になってきます。
コピペだけで出来ると言ってきましたが、それだけで競馬AIが出来てしまったら、みんなが精度の高いAIを持てるようになってしまい優位性がなくなってしまいます。
他の人より優れた予想をしたいのであれば、勉強してモデルを改善していく必要があります。
勉強するのであれば、最近発売された以下の書籍がおススメです!

まとめ
パラメータの修正を行わなければ、コピペで学習したモデルの作成が完了したと思います。
パラメータの組み合わせは無限と感じるほど多く、すべての組み合わせを試すのは無理だったのではないかと思います。
モデルを作成するのにも時間がかかりますし。
自動でパラメータチューニングする方法もあるので、またの機会にそちらのコードも記事にしようかと思います。
次は実際のレースデータを活用し、予測する方法について説明します。

予想した結果はこちらで公開中!



コメント
オッズ1や2などの数字が後ろについている特徴量は何を表しているのでしょうか?
1走前のオッズ、2走前のオッズという意味です。この連番はすべての特徴量共通で、5走前までの情報を持っています。
返信ありがとうございます!
もう一つ質問なのですが、結果の確認のところに8万レースを予想してとありますが、どのレースの予想なのでしょうか?
すみません。8万レースと書きましたが、正しくは「8万頭の順位を予想」が正しいです。
失礼しました。
お世話になっております。上記コマンドを実行したところ、下記エラーメッセージとなりました。
(base) ren@rennoMacBook-Pro ~ % /Users/ren/anaconda3/bin/python /Users/ren/Pictures/data/estimation.py
[LightGBM] [Warning] min_data_in_leaf is set=190, min_child_samples=20 will be ignored. Current value: min_data_in_leaf=190
zsh: segmentation fault /Users/ren/anaconda3/bin/python
ネットで調べても原因がわからず。。。これ何が原因なのでしょうか?
パラメーターの設定がおかしいみたいですね。
warningなので学習自体はできていると思いますが。
min_data_in_leafを190にすると、min_child_samplesの20は無視すると言っているので、パラメーターを調整してみてください。
warningを消すだけならmin_child_samplesを消すだけで解消すると思います。
lightgbmインストールしてなかったのが原因でした。。おかげで実行できました。ありがとうございました。
質問です。
ふと疑問に思ったことなのですが、例えば学習データにない馬が初出場するレースがあった場合はどうするのでしょうか。そのままのコードで予想できるのでしょうか。
そのままのコードで予想できますが、初出走の場合過去のレースデータがないので予測の精度は下がってしまいます。
いつもありがとうございます。お世話になっています。
3つ質問があります。
①estimation.pyについて
# 特徴量とターゲットの分割
train, test = split_date(data, 0.3)
X_train = train.drop([‘着順’,’オッズ’,’人気’,’上がり’,’走破時間’,’通過順’], axis=1)
y_train = train[‘着順’]
X_test = test.drop([‘着順’,’オッズ’,’人気’,’上がり’,’走破時間’,’通過順’], axis=1)
y_test = test[‘着順’]
上記は不要な特徴量を削除してターゲット(着順)を予想するという認識であっているでしょうか。
②また予想のレベルアップのためにLightGBMを学びたいのですがおすすめの教材、ユーチューブなどはあったりしますか?
③encode.pyについて
categorical_features = [‘馬’, ‘騎手’, ‘レース名’, ‘開催’, ‘場名’, ‘騎手1’, ‘騎手2’, ‘騎手3’, ‘騎手4’, ‘騎手5’] # カテゴリカル変数の列名を指定してください
この値は何に役使われているのでしょうか。
1.
「不要な特徴量を削除してターゲット(着順)を予想するという認識」であっています。
trainは学習用に使われるデータ、testはテスト用データに分けられています。
2.
https://www.youtube.com/@user-ej3zj6kv9z
https://pc-keiba.com/wp/lightgbm/
私はこの動画やサイトから開発を始めました。
レベルアップになるかどうかは分かりませんが!
3.
categorical_featuresは文字列のデータを指定しています。
そのままでは予想できないので、日本語を数字に変換しています。
python初心者です。
すみません。教えてください。
estimation.pyを実行したところ以下のエラーが発生しました。
お手数ですが解決方法を教えてください。
AttributeError: module ‘matplotlib’ has no attribute ‘get_data_path’
環境はVSCodeです。
matplotlibは最新のバージョンで実行してます。
環境上のエラーのようなので、私の方では回答が難しいのでご自身で調べていただけますでしょうか?
以下のサイトで同じエラーについて記載されています。
https://stackoverflow.com/questions/63826975/attributeerror-module-matplotlib-has-no-attribute-get-data-path-on-visual-s