
最近話題のChatGPTを生み出したOpenAIが2022年9月にリリースした「Whisper(ウィスパー)」というツールをご存知でしょうか?
WhisperはAIによって音声を解析し、文字起こしをしてくれるツールです。
今回はこちらを使って、テレビ会議の録画ファイルを文字起こししてみようと思います。
文字起こしできれば、議事録作成の手間が省けるし、ChatGPTに要約をお願いすれば・・・なんて夢が広がりますね!
では、さっそくやってみましょう!
Whisperのサイトはこちら
Google Colaboratoryの準備
Colabとはブラウザ上でPythonを記述、実行できるツールです。
環境構築が不要なのでサクッと試したいときに便利です。
Googleアカウントをお持ちであれば誰でも使うことができます。
Google Colaboratory
ノートブックを新規作成
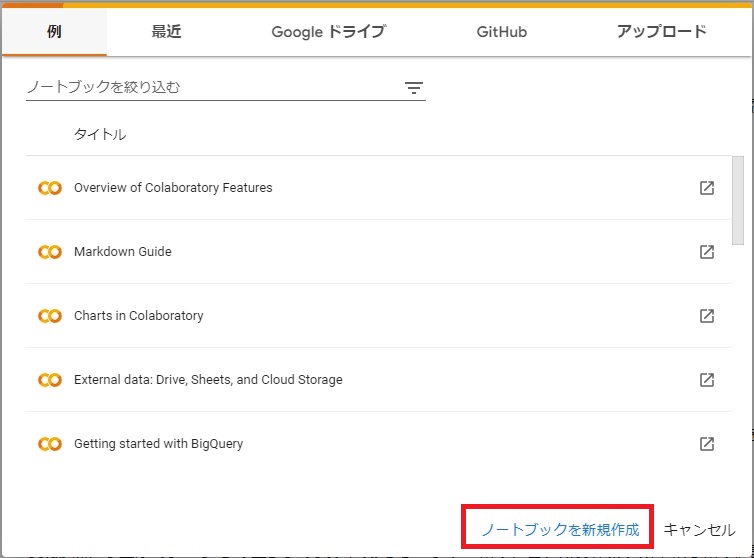
ランタイムの接続
接続をクリックする。
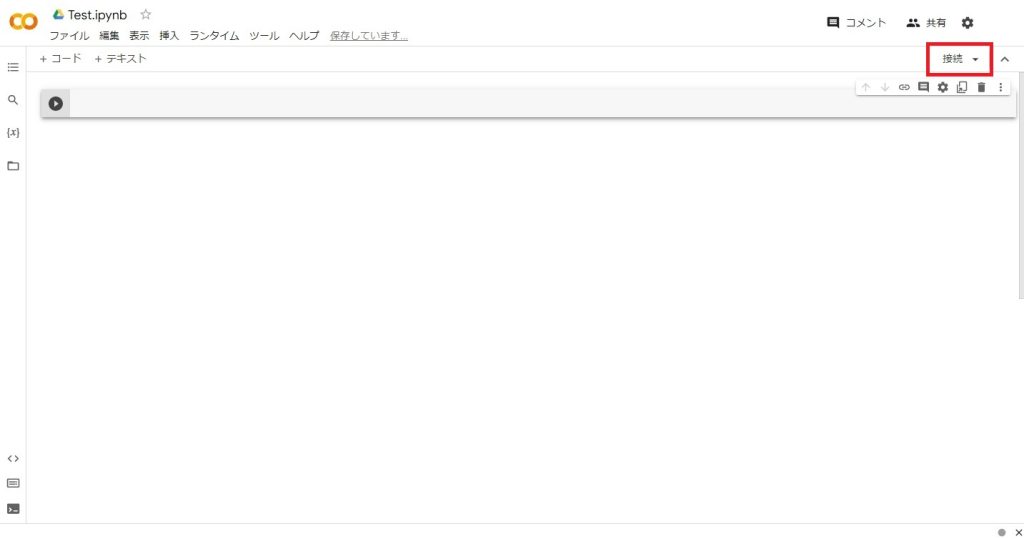
接続が完了すると「RAM ディスク」と変わるので、そこをクリックする。
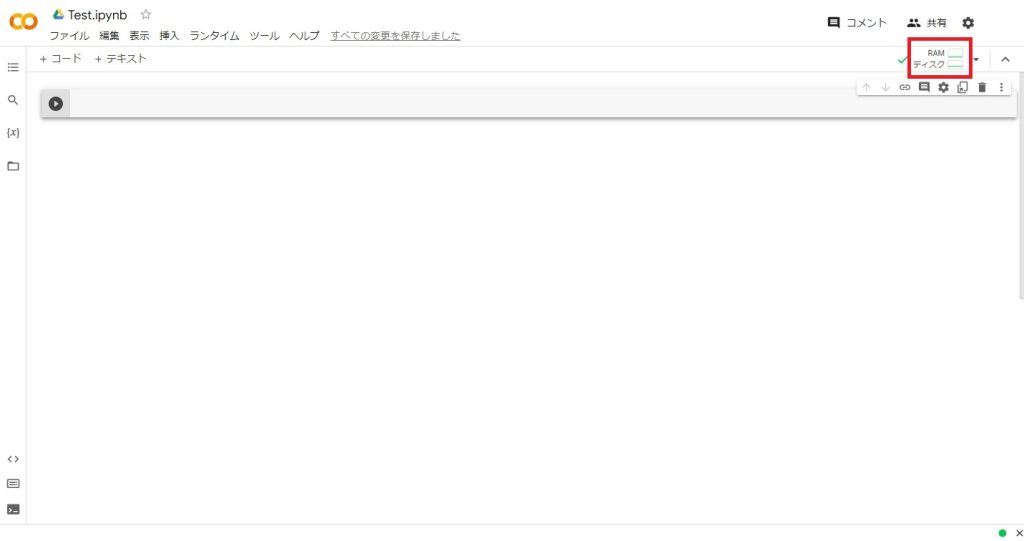
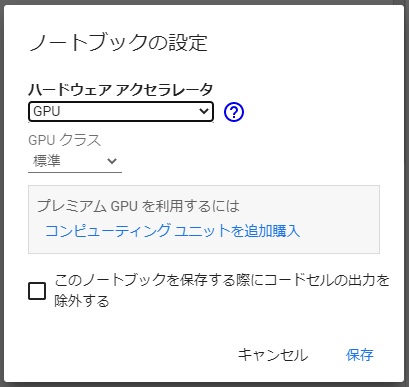
「ランタイムのタイプを変更」をクリックする。
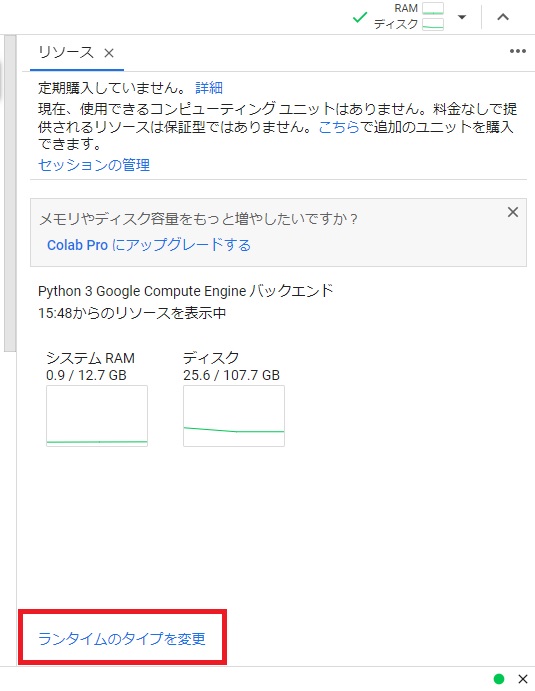
ハードウェアアクセラレータを「GPU」に変更し保存する。
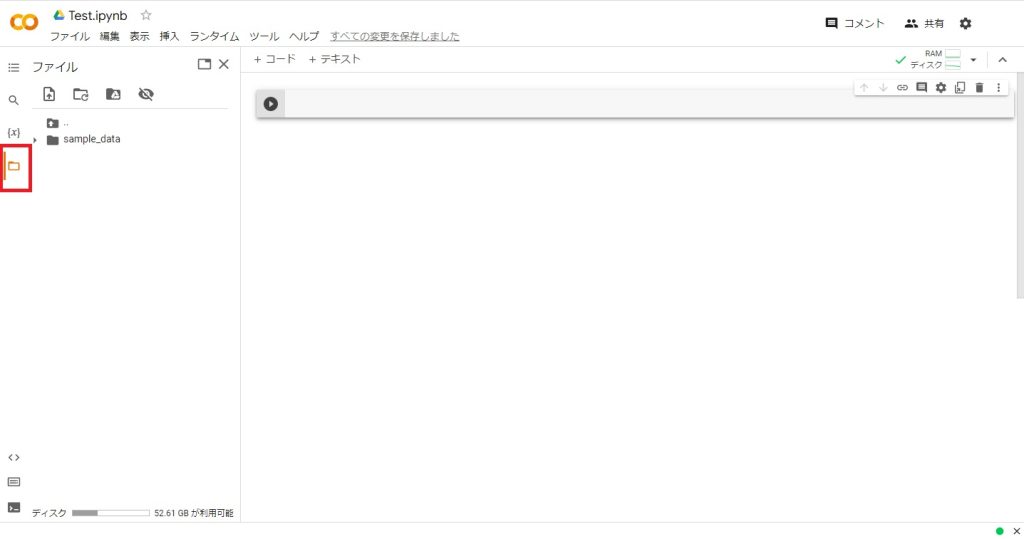
フォルダとファイルの準備
赤枠のフォルダアイコンをクリックし、解析を行うファイルやダウンロード用フォルダを準備する。
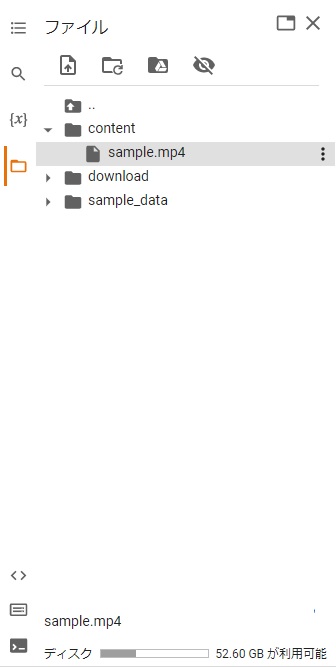
以下の通り作成してください。
Whisperを使い解析するコードを記述する
コードの内容
コードは以下の通り。
ブロックごとに記述していってください。
!pip install git+https://github.com/openai/whisper.gitimport whisper
fileName = "sample.mp4"
lang = "ja"
model = whisper.load_model("large")
# Load audio
audio = whisper.load_audio(f"content/{fileName}")
result = model.transcribe(audio, verbose=True, language=lang)
# Write into a text file
with open(f"download/{fileName}.txt", "w") as f:
f.write(f"▼ Transcription of {fileName}\n")
f.write(result["text"])from google.colab import files
!zip -r download.zip download
files.download("download.zip")・少しだけコードの補足
Whisperのモデルは5種類あります。(tiny、base、small、mudium、large)
学習データの差なので、右に行けば行くほど高精度になっています。
ただ消費するメモリも増加していくので注意してください。
真ん中あたりにあるコード「transcribe」は全文書き出すというもの。他の書き方だと30秒までしか書き出しされません。
画像だとこの通り。
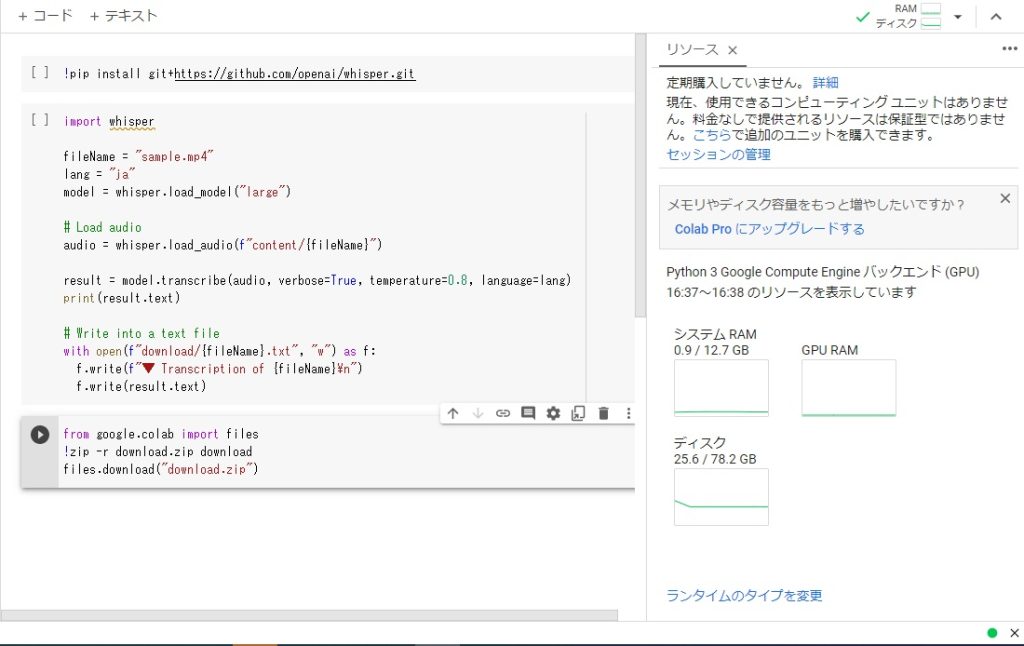
コードの実行
あとは上から順番に実行していくだけ。
▶ボタンを上からクリックしていってください。
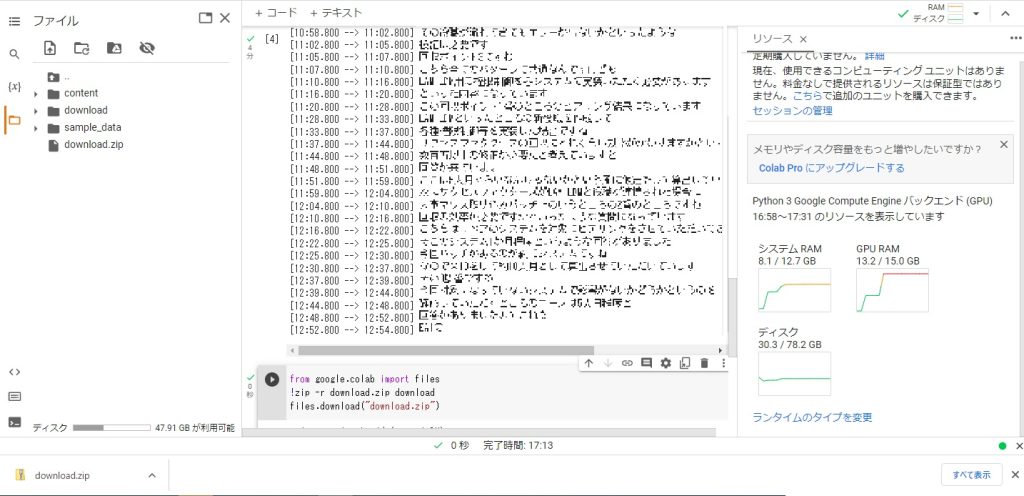
実行するとzipファイルがダウンロードされます。
回答して中を確認すると、解析されたテキストファイルが格納されています。
結果について
録画ファイルは全体で30分ほどあるのですが、解析されたのは13分弱という結果でした。
無料版のColabだとメモリが足りないのか、会議全体を書き出すのは難しいみたいです。何度かチャレンジしましたがダメでした。
また、書き出される分数もバラバラでした。
会議は1時間程度のものがほとんどだと思いますので、無料版では使えないという結果になりました。
本格的に実行したいのであれば、有料版にするか、自分で実行環境を構築するかになりそうです。
自分で実行環境を構築して試してみる機会があればまた紹介します。
録画ファイルからChatGPTを使って議事録の自動生成が出来るまではもう少しチャレンジが必要みたいです。
ちなみに精度ですが、largeだと大体あっているなという感覚です。聞き取りづらい言葉もあるので間違いはところどころありますが、それでもかなりの精度だと思います。
精度のほどは実際に試してみてください。
最後までお読みいただきありがとうございました。
追記-全体を書き出せなかった原因
よくよく調べてみるとWhisper APIが受け付けているファイルサイズは25MB以下という制限があったみたいです。
無料版Colabのせいではありませんでした。。。
全部を書き出せないもの、分数がバラバラで安定しないものがファイルサイズが大きかったせいでした。
ちなみにファイルサイズは150MBありました。
次回は録画ファイルから音声データの抽出、データの圧縮を試してみてその結果を紹介します。


コメント