前回までの記事
【OpenAI】WhisperとGoogle Colaboratoryで録画ファイルの文字起こし
【FFmpeg】録画ファイルを音声だけにしてファイルサイズを下げる方法
音声ファイルのサンプルレートを下げるだけでは、OpenAIのWhisperで解析しきることができなかったため、分割してAPIに渡したいと思います。
その為、ファイル分割を行いたいのですが、話途中で分割してしまうと誤変換されてしまう可能性があるので、無音区間で分割します。
さらに、Whisperに渡すために25MB以下になるようにします。
Google Colaboratoryで分割する
Colabを立ち上げる
使い方は下記の記事を参考にしてください。
【OpenAI】WhisperとGoogle Colaboratoryで録画ファイルの文字起こし
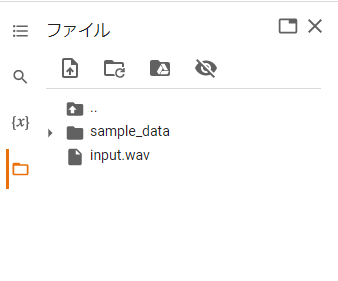
ファイルを準備する
画像の通りの場所に音声ファイルをアップロードしてください。
コードを入力する
下記のコードをColabに入力してください。
!pip install pydubimport os
import subprocess
import sys
import pydub
from pydub import AudioSegment
from pydub.silence import split_on_silence
src_file = "input.wav"
work_dir = "work"
os.makedirs(work_dir, exist_ok=True)
max_file_size = 25 * 1000 * 1000 * 0.9 # Whisper APIに送信できるのは25MBまで。10%ほどブレを見込んでおく。
# split_on_silenceで分割する際のパラメータ。適宜調整。
min_silence_len = 500
keep_silence = 500
silence_thresh = -90
sound = AudioSegment.from_file(src_file, format="wav")
total_length = len(sound)
total_size = os.path.getsize(src_file)
max_length = total_length * (max_file_size / total_size) # ファイルサイズと時間から、分割する最大時間を取得する
# 無音部分をカットして分割
chunks = split_on_silence(
sound,
min_silence_len=min_silence_len,
silence_thresh=silence_thresh,
keep_silence=keep_silence,
)
num_of_chunks = len(chunks)
def output_mp3(chunk, output):
chunk.export(output, format="wav")
s = AudioSegment.from_file(output, "wav")
# 分割したチャンクをmax_lengthごとに結合
current_chunk = None
for i, c in enumerate(chunks):
if current_chunk is None:
current_chunk = c
continue
temp_chunk = current_chunk + c
outFilePath = f"{work_dir}/out_{i + 1}.wav"
if len(temp_chunk) > max_length:
output_mp3(current_chunk, outFilePath)
current_chunk = c
else:
if i == len(chunks) - 1:
output_mp3(temp_chunk, outFilePath)
else:
current_chunk += c実行する
上から順番に実行してください。
実行が完了するとworkフォルダが作成され、「out_〇〇.wav」というファイルが複数できていると思います。
これだけで簡単に音声ファイルの分割ができてしまいます。
ぜひやってみてください。


コメント