
私は趣味で横浜DeNAベイスターズを応援しているのですが、ベイスターズ選手だけの交流戦の打撃成績、投手成績はどうだったのかな?と気になりまして、調べました。
全チームの交流戦打者成績(規定打席以上)や選手個別の成績はあったのですが、ベイスターズ選手の成績一覧を表示してくれるサイトが見つかりませんでした。
そこで自分で情報を抽出し一覧を作ろうと今回Webスクレイピングを試してみました。
手作業ではやりたくないですしね、、、
環境準備(Windows)
以下に示したものが必要なので、持っていないものがあればインストールしてください。
コードエディタ
- Visual Studio Code
このサイトが参考になります。
パッケージ
- Python
このサイトが参考になります。
ライブラリ
- beautifulsoup4
- requests
以下のコマンドでインストールできます。
pip install beautifulsoup4pip install requestsもしpipが古いよーとメッセージが出たらアップグレードしてください。
py -m pip install --upgrade pipコーディング
今回取得するサイト
nf3 – Baseball Data House – さんから取得させていただきいました。ありがとうございます!
欲しいデータは以下の画面のそれぞれの選手詳細の全打席成績データなので、まずはURL構造とHTML構造を確認します。
URLの確認
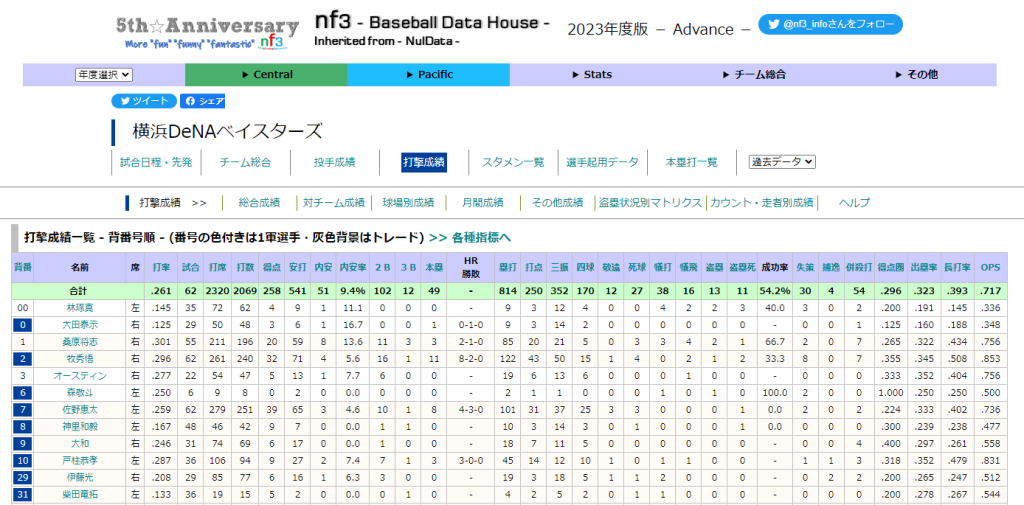
選手詳細ページの中の全打席成績ページURLはこうなっていました。
林琢真選手
https://nf3.sakura.ne.jp/php/stat_disp/stat_disp.php?y=0&leg=0&fpnum=00&tm=DB&mon=0&vst=all大田泰示選手
https://nf3.sakura.ne.jp/php/stat_disp/stat_disp.php?y=0&leg=0&fpnum=0&tm=DB&mon=0&vst=allURLを見比べるとfpnum=〇の値が背番号になっていることがわかります。
こういうURLの場合は簡単ですね!ループさせながら番号を変えていくだけで取得できます。
HTML構造の確認
次にHTML構造の確認をしていきます。
欲しいデータは以下のテーブルの部分なので、どのような構造になっているかブラウザの開発者ツールを使って確認します。

開発者ツールの開き方は2通り(今回はGoogle Chromeでやっています)
・F12キーを押す
・右クリックして表示されたメニューの検証を押す
対象のHTMLを見つけ出し、コードを確認します。
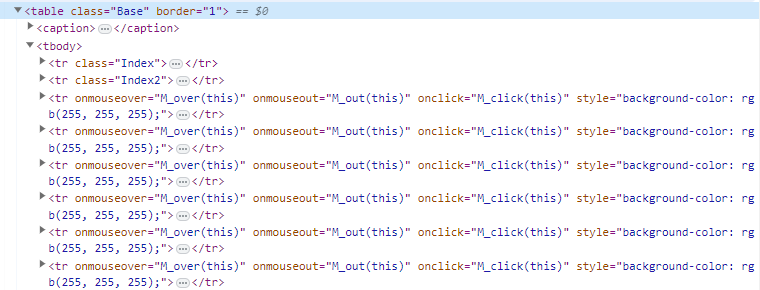
構造を見ると、以下のようなことがわかりました。
・table tr tdタグで構成されている
・欲しいテーブルには”Base”というクラスがついている
・1段目のヘッダーには”Index”、2段目のヘッダーには”Index2″というクラスがついている
あとはこの情報をもとに実際にスクレイピングしていきます。
スクレイピングの説明
スクレイピングの仕組みは先ほどインストールした”requests“でWebページの情報を取得し、”BeautifulSoup“でHTMLデータを抽出します。
url = "https://○○○○.com"
# Webページの情報を取得する
response = requests.get(url)
# 取得したWebページのテキスト
html = response.text
# BeautifulSoupを使ってHTMLを解析する
soup = BeautifulSoup(html, 'html.parser')もうこれだけでHTMLデータが取得できてしまいます。
あとはHTMLの基本的な知識は必要なのですが、欲しいHTMLタグを指定して取得します。
# テーブルを取得する
table = soup.find('table', class_='Base')
# テーブル内の行を取得する
rows = table.find_all('tr')
# 行から値の入ったセルを取得する
cells = row.find_all('td')
# セルからテキストを取得する
cells[i].text #←セルは複数あるのでループでテキストを取り出します(だから[i]がある)今回はtableとその中のtrが欲しかったので指定しています。
同じHTMLタグが複数あり、欲しいところだけを抽出するために、classも指定しています。
findでは引数に一致する最初の一つの要素を取得します。
find_allでは引数に一致するすべての要素を取得します。
このあたりだけ知っていれば、あとは実際にWebページ構成を見て、欲しい要素を指定するだけなのでできると思います。
あと、次のソースに記載がある”.get(“class”)“は対象の要素のクラスを取得することが出来ます。
このクラスを持っている場合はこうしたいな、みたいな判断に使います。
コピペでスクレイピング実行
スクレイピングの説明は以上です。
後は取得したHTMLから取り出したテキストを欲しい形に加工していきます。
次のプログラムをコピペして実行すれば取得できます。
URLは先ほど確認したようにループで番号を変えながら実行しています。
import requests
from bs4 import BeautifulSoup
import csv
# スクレイピングしたデータを格納するリストを作成する
data_list = []
players = {
"00": "林琢真",
"0": "大田泰示",
"1": "桑原将志",
"2": "牧秀悟",
"3": "オースティン",
"5": "松尾汐恩",
"6": "森敬斗",
"7": "佐野恵太",
"8": "神里和毅",
"9": "大和",
"10": "戸柱恭孝",
"11": "東克樹",
"12": "阪口皓亮",
"13": "伊勢大夢",
"14": "石田健大",
"15": "徳山壮磨",
"16": "大貫晋一",
"17": "三嶋一輝",
"18": "小園健太",
"19": "山﨑康晃",
"20": "坂本裕哉",
"21": "今永昇太",
"22": "入江大生",
"23": "藤田一也",
"24": "吉野光樹",
"26": "濵口遥大",
"27": "上茶谷大河",
"29": "伊藤光",
"30": "三浦銀二",
"31": "柴田竜拓",
"32": "益子京右",
"33": "粟飯原龍之介",
"34": "平田真吾",
"35": "橋本達弥",
"36": "森下瑠大",
"37": "楠本泰史",
"38": "田中俊太",
"40": "松本隆之介",
"41": "櫻井周斗",
"42": "アンバギー",
"43": "深沢鳳介",
"44": "小深田大地",
"45": "ガゼルマン",
"46": "田中健二朗",
"47": "笠原祥太郎",
"48": "京山将弥",
"49": "J.B.ウェンデルケン",
"50": "山本祐大",
"51": "宮﨑敏郎",
"53": "池谷蒼大",
"56": "髙田琢登",
"57": "東妻純平",
"58": "梶原昂希",
"59": "平良拳太郎",
"60": "知野直人",
"61": "蝦名達夫",
"62": "エスコバー",
"63": "関根大気",
"64": "中川虎大",
"65": "宮國椋丞",
"67": "西巻賢二",
"68": "森原康平",
"92": "宮城滝太",
"95": "石川達也",
"96": "バウアー",
"98": "京田陽太",
"99": "ソト"
}
done = False # doneを初期化
# ページ数を指定してスクレイピングを実行する関数を定義する
def scrape_page(uniform_num):
global done # doneを関数内でグローバル変数として使用する
player_name = players.get(uniform_num)
# URLを構築する
url = 'https://nf3.sakura.ne.jp/php/stat_disp/stat_disp.php?y=0&leg=0&fpnum=' + uniform_num +'&tm=DB&mon=0&vst=all'
# HTMLを取得する
response = requests.get(url)
html = response.text
# BeautifulSoupを使ってHTMLを解析する
soup = BeautifulSoup(html, 'html.parser')
# テーブルを取得する
table = soup.find('table', class_='Base')
# テーブル内の行を取得する
rows = table.find_all('tr')
#存在しない背番号の場合
if(len(rows) <= 3):
return
# データを抽出してリストに追加する
for row in rows:
head = row.find_all('th')
if row.get("class") and "Index2" in row["class"]:
continue # "Index2"クラスを持つ行をスキップする
if len(head) != 0:
if done:
continue
#不要な列の指定
cells_to_exclude = [5, 6, 17, 18, 19]
th_data = [head[i].text for i in range(len(head)) if i not in cells_to_exclude]
th_data.insert(0, '選手名')
data_list.append(th_data)
done = True
continue
cells = row.find_all('td')
#不要な列の指定
cells_to_exclude = [5, 6, 7, 8, 9, 20, 21, 22, 23, 24, 25]
data = [cells[i].text for i in range(len(cells)) if i not in cells_to_exclude]
data.insert(0, player_name)
data_list.append(data)
# ページ数の範囲を指定してスクレイピングを実行する
start_page = 0
end_page = 100
total = end_page - start_page - 1
for page in range(start_page, end_page):
uniform_num = str(page)
print('\r'+ uniform_num + '/' + str(total), end='')
#0の時は2周する様に。林対応
if uniform_num == '0':
scrape_page('00')
scrape_page(uniform_num)
# データをCSVファイルに出力する
with open('data.csv', 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
for data in data_list:
writer.writerow(data)やったこととしては、
選手名がテーブル内にはなかったので、背番号から名前を取得できるようにdictionaryを作成したこと
2段目のヘッダーが不要だったのでスキップするようにしたこと
存在しない背番号の時にエラーにならないようにテーブルが3行以下の場合はスキップした
林選手の場合の特別処理(00は数字ではないので)
ミスった箇所
結果には影響ないのですが、せっかくdictionaryを作ったのであれば、背番号のキーでループすれば、無駄な背番号での検索や、林選手の特別処理はいらなかったな、、と反省。
スクレイピングは相手のサイトにもご迷惑をおかけしてしまう可能性があるので、できるだけ無駄なリクエストは避けた方が良いです。
実行結果
CSVデータ
実行すると以下のようなcsvが作成されたのではないでしょうか。
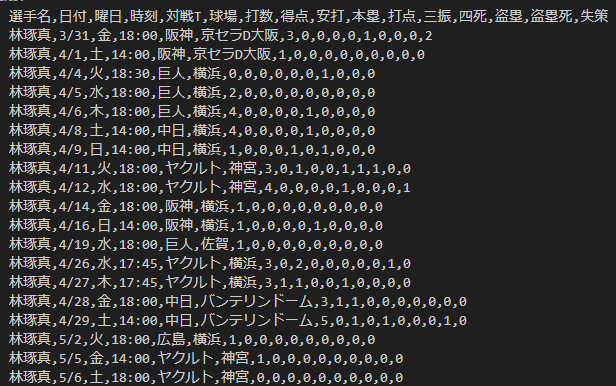
あとは交流戦期間で指定して打数、安打、本塁打、打点などなどを合算し、打率を算出して完成です。
おまけのデータ加工コード
データを加工するには以下のコードをコピペで先ほどのファイルとは別ファイルで保存し実行してみてください。
import csv
from datetime import datetime
# データを読み込む
data_list = []
with open('data.csv', 'r', newline='', encoding='utf-8') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
data_list.append(row)
# データを日付単位で処理し、打数、安打、本塁、打点を合算する
player_stats = {}
date_format = '%m/%d'
start_date = datetime.strptime('5/30', date_format) # 期間の開始日付
end_date = datetime.strptime('6/19', date_format) # 期間の終了日付
for data in data_list[1:]:
player_name = data[0]
date = datetime.strptime(data[1], date_format)
# 期間内のデータのみ処理する
if start_date <= date <= end_date:
at_bats = int(data[6])
hits = int(data[8])
home_runs = int(data[9])
rbis = int(data[10])
if at_bats > 0: # 打数が0でない場合のみ処理する
if player_name not in player_stats:
player_stats[player_name] = {'at_bats': at_bats, 'hits': hits, 'home_runs': home_runs, 'rbis': rbis}
else:
player_stats[player_name]['at_bats'] += at_bats
player_stats[player_name]['hits'] += hits
player_stats[player_name]['home_runs'] += home_runs
player_stats[player_name]['rbis'] += rbis
# 打率を算出し、結果をCSVファイルに出力する
with open('player_stats.csv', 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['選手名', '打数', '安打', '本塁', '打点', '打率'])
for player_name, stats in player_stats.items():
at_bats = stats['at_bats']
hits = stats['hits']
batting_average = hits / at_bats if at_bats > 0 else 0
writer.writerow([player_name, at_bats, hits, stats['home_runs'], stats['rbis'], f'{batting_average:.3f}'])
こんなところでも大活躍!ChatGPT
いろいろと説明してきましたが、実はChatGPTの力をかなりお借りして実装しています。
ChatGPTはプログラミングが大得意なんです。
こんなhtmlをスクレイピングしたいんだけど教えて!ってお願いしたら丁寧に教えてくれます。

もちろんこのまま動くわけではないのですが、サンプルソースとしては十分すぎるものです。
エラーが出た時には以下のようにエラーメッセージを入れるだけで、原因と修正方法まで教えてくれちゃいます。
こんな形でChatGPTとやり取りしながらコーディングすれば爆速で実装することが出来ます。
まとめ
今回はPythonを使ってWebスクレイピングを説明しました。この技術を使えば、Webサイトから欲しい情報を取得して、欲しい形に加工することが出来ます。
ChatGPTに聞きながら実装したのでズルく見えたかもしれませんが、これからのプログラミングはChatGPTを活用しながら実装するのが主流になってくると思います。
回答が爆速だし、エラーも調査してくれるし。ただし必ず正しい答えを返してくれるわけではないので、チェックできる多少の知識と検証は必要になってきます。
仕事で活用する場合はお客様の情報や社外秘情報、個人情報などを入力しないように注意してくださいね!


コメント