
こちらの記事にある予想するレースデータの取得方法の更新記事です。

久しぶりの競馬AIの記事になります。
競馬AI④の予想するレースデータの取得まで実施した方は、データの整理が大変だと感じませんでしたか?
私自身感じていたので、簡単に取得できるように今回のプログラムを作成していました。
今回はそのプログラムを紹介するので、参考にしつつ使ってください。
改良点
そのまま予想に掛けられる形に整形した状態での出力
これまではレースに出走する馬の過去5レースのデータを取得するだけのプログラムでした。
それを対象のレース情報から出走馬の過去5レースまですべて取得するように修正しました。
1場すべてのレースを取得できるように修正
1レースごとの取得ではなく、ループ処理を入れることで場ごとに12レースすべてのレースを取得できるように修正しました。
走破時間を標準化するように修正
encodeでは標準化して学習させていたのに対し、予想対象の出走馬の過去レースの走破時間は標準化していなかったため、標準化するようを修正しました。
※encode.pyの修正が必要になります。
こちらの記事を更新したので、差分を確認し更新してください。

修正プログラム
プログラム
修正したプログラムは以下の通りです。
※プログラムを読んで足りないフォルダなどがあれば作成してください
from bs4 import BeautifulSoup
import requests
from datetime import datetime
import numpy as np
import csv
import sys
import re
import statistics
import pandas as pd
def class_mapping(row):
mappings = {'障害':0, 'G1': 10, 'G2': 9, 'G3': 8, '(L)': 7, 'オープン': 7, 'OP': 7, '3勝': 6, '1600': 6, '2勝': 5, '1000': 5, '1勝': 4, '500': 4, '新馬': 3, '未勝利': 1}
for key, value in mappings.items():
if key in row:
return value
return 0 # If no mapping is found, return 0
#対象レースデータの取得
race_date = "2023/8/26"
racecourse='niigata'
#下2桁(レースID)は消す
main_page_url = "https://race.netkeiba.com/race/shutuba.html?race_id=2023040305"
start = 11
end = 12
# CSVから平均と標準偏差を読み込む
time_df = pd.read_csv('config/standard_deviation.csv', index_col=0)
mean1, mean2 = time_df['Mean']['First Time'], time_df['Mean']['Second Time']
std1, std2 = time_df['Standard Deviation']['First Time'], time_df['Standard Deviation']['Second Time']
for race_no in range(start, end):
race_num = str(race_no).zfill(2)
race_id = main_page_url.split("=")[-1] + race_num
response = requests.get(main_page_url + race_num)
soup = BeautifulSoup(response.content, "html.parser")
#新馬戦は除外する
racename = soup.find("h1", class_="RaceName")
print(racename.text.strip())
if "新馬" in racename.text.strip() or "2歳未勝利" in racename.text.strip():
continue
# "RaceData01"クラスのdivを検索
element = soup.find("div", class_="RaceData01")
# 該当要素からテキストを取得
text = element.text if element else ""
# テキストからコース種別、距離、方向、天候を抽出
direction = re.search(r"(左|右|直|芝)", text).group() if re.search(r"(左|右|直|芝)", text) else ""
weather = re.search(r"天候:(\w+)", text).group(1) if re.search(r"天候:(\w+)", text) else ""
span = element.find("span").text.strip()
distance = span[1:-1]
shiba_mapping = {'芝': 0, 'ダ': 1, '障': 2}
track = shiba_mapping.get(span[0])
mawari_mapping = {'右': 0, '左': 1, '芝': 2, '直': 2}
mawari = mawari_mapping.get(direction)
babaSpan = soup.find("span", class_="Item04")
baba = ""
if soup.find("span", class_="Item04") is not None:
baba = babaSpan.text.strip()[-1]
baba_mapping = {'良': 0, '稍': 1, '重': 2, '不': 3}
baba = baba_mapping.get(baba)
tenki_mapping = {'晴': 0, '曇': 1, '小': 2, '雨': 3, '雪': 4}
tenki = tenki_mapping.get(weather)
race_data = soup.find("div", class_="RaceData02")
# spanタグのリストを取得します
spans = race_data.find_all('span')
# 2番目のspanタグ(インデックスは0から始まるため1を指定)のテキストを取得します
location = spans[1].text
place = ""
if location == "札幌":
place = "01"
elif location == "函館":
place = "02"
elif location == "福島":
place = "03"
elif location == "新潟":
place = "04"
elif location == "東京":
place = "05"
elif location == "中山":
place = "06"
elif location == "中京":
place = "07"
elif location == "京都":
place = "08"
elif location == "阪神":
place = "09"
elif location == "小倉":
place = "10"
# "RaceName"クラスのdivを検索
divRaceName = soup.find("h1", class_="RaceName")
#レース名
race_name = divRaceName.text.strip()
#クラス
race_rank = ""
if soup.find("span", class_="Icon_GradeType1") is not None:
race_rank = 10
elif soup.find("span", class_="Icon_GradeType2") is not None:
race_rank = 9
elif soup.find("span", class_="Icon_GradeType3") is not None:
race_rank = 8
elif soup.find("span", class_="Icon_GradeType15") is not None:
race_rank = 7
elif soup.find("span", class_="Icon_GradeType16") is not None:
race_rank = 6
elif soup.find("span", class_="Icon_GradeType17") is not None:
race_rank = 5
elif soup.find("span", class_="Icon_GradeType18") is not None:
race_rank = 4
else:
race_rank = class_mapping(race_name)
all_results = [] # 全てレース結果を保存するためのリスト
all_results.append(["race_id","馬","騎手","馬番","走破時間","オッズ","通過順","着順","体重","体重変化","性","齢","斤量","上がり","人気","レース名","日付","開催","クラス","芝・ダート","距離","回り","馬場","天気","場id","場名","日付1","馬番1","騎手1","斤量1","オッズ1","体重1","体重変化1","上がり1","通過順1","着順1","距離1","クラス1","走破時間1","芝・ダート1","天気1","馬場1","日付2","馬番2","騎手2","斤量2","オッズ2","体重2","体重変化2","上がり2","通過順2","着順2","距離2","クラス2","走破時間2","芝・ダート2","天気2","馬場2","日付3","馬番3","騎手3","斤量3","オッズ3","体重3","体重変化3","上がり3","通過順3","着順3","距離3","クラス3","走破時間3","芝・ダート3","天気3","馬場3","日付4","馬番4","騎手4","斤量4","オッズ4","体重4","体重変化4","上がり4","通過順4","着順4","距離4","クラス4","走破時間4","芝・ダート4","天気4","馬場4","日付5","馬番5","騎手5","斤量5","オッズ5","体重5","体重変化5","上がり5","通過順5","着順5","距離5","クラス5","走破時間5","芝・ダート5","天気5","馬場5"])
# テーブルを指定
table = soup.find("table", {"class": "Shutuba_Table"})
# テーブル内の全ての行を取得
main_rows = table.find_all("tr")
url_list = []
# 各行から必要な情報を取り出し
for i, row in enumerate(main_rows[2:], start=1):# ヘッダ行をスキップ
cols = row.find_all("td")
umaban = cols[1].text.strip()
sign = cols[2].text.strip()
if sign == "除外":
continue
uma = cols[3].text.strip()
a_tag = cols[3].find('a')
url = a_tag.get('href')
url_list.append(url)
a_tag2 = cols[6].find('a')
url2 = a_tag2.get('href')
response = requests.get(url2)
soup = BeautifulSoup(response.content, "html.parser")
element2 = soup.find("div", class_="db_head_name")
h1_text = element2.find('h1').get_text(strip=True)
name = h1_text.split("\u00a0")[0]
kishu = re.sub(r'[A-Za-z.]', '', name)
odds = cols[9].find("span").text.strip()
pop = cols[10].find("span").text.strip()
#体重
horse_weight = cols[8].text.strip()
weight = 0
weight_dif = 0
try:
weight = int(horse_weight.split("(")[0])
weight_dif = int(horse_weight.split("(")[1][0:-1])
except:
weight = ''
weight_dif = ''
weight = weight
weight_dif = weight_dif
#斤量
handicap = cols[5].text.strip()
#性
sex = cols[4].text.strip()[0]
sex_mapping = {'牡':0, '牝': 1, 'セ': 2}
sex = sex_mapping.get(sex)
#齢
age = cols[4].text.strip()[1]
result = [race_id, uma, kishu, umaban, "", odds, "", "", weight, weight_dif, sex,
age, handicap, "",pop, race_name, race_date, location, race_rank, track, distance,
mawari, baba, tenki, place, location]
all_results.append(result)
# 現在の日付を取得
now = datetime.now()
# cutoff_date を datetime 型に変換
cutoff_date = datetime.strptime(race_date, '%Y/%m/%d')
for index ,url in enumerate(url_list):
results = [] # 馬単位のレース結果を保存するためのリスト
response = requests.get(url)
# ステータスコードが200以外の場合はエラーが発生したとみなし、処理をスキップ
if response.status_code != 200:
print(f"Error occurred while fetching data from {url}")
continue
soup = BeautifulSoup(response.content, "html.parser")
# テーブルを指定
table = soup.find("table", {"class": "db_h_race_results nk_tb_common"})
# テーブル内の全ての行を取得
rows = ''
try:
rows = table.find_all("tr")
except:
continue
# 各行から必要な情報を取り出し
for i, row in enumerate(rows[1:], start=1):# ヘッダ行をスキップ
cols = row.find_all("td")
# 日付を解析
str_date = cols[0].text.strip()
date = datetime.strptime(str_date, '%Y/%m/%d')
# 特定の日付より前のデータのみを取得
if date < cutoff_date:
# 取得したいデータの位置を指定し取得
#体重
horse_weight = cols[23].text.strip()
weight = 0
weight_dif = 0
try:
weight = int(horse_weight.split("(")[0])
weight_dif = int(horse_weight.split("(")[1][0:-1])
except:
weight = ''
weight_dif = ''
weight = weight
weight_dif = weight_dif
#上がり
up = cols[22].text.strip()
#通過順
through = cols[20].text.strip()
try:
numbers = list(map(int, through.split('-')))
through = sum(numbers) / len(numbers)
except ValueError:
through = ''
#着順
order_of_finish = cols[11].text.strip()
try:
order_of_finish = str(int(order_of_finish))
except ValueError:
order_of_finish = ""
#馬番
past_umaban = cols[8].text.strip()
#騎手
past_kishu = cols[12].text.strip()
#斤量
past_kinryo = cols[13].text.strip()
#距離
distance = cols[14].text.strip()
#芝・ダート
track = distance[0]
shiba_mapping = {'芝': 0, 'ダ': 1, '障': 2}
track = shiba_mapping.get(track)
#距離
distance = distance[1:]
#レース名
race_name = cols[4].text.strip()
race_rank = class_mapping(race_name)
#タイム
time = cols[17].text.strip()
try:
time = float(time.split(':')[0]) * 60 + sum(float(x) / 10**i for i, x in enumerate(time.split(':')[1].split('.')))
except:
time = ''
if not time == '':
# 1回目の平均と標準偏差で標準化
time = -((time - mean1) / std1)
# 外れ値の処理:-3より小さい値は-3に、2.5より大きい値は2に変換
time = -3 if time < -3 else (2 if time > 2.5 else time)
# 2回目の平均と標準偏差で標準化
time = (time - mean2) / std2
#天気
weather = cols[2].text.strip()
tenki_mapping = {'晴': 0, '曇': 1, '小': 2, '雨': 3, '雪': 4}
weather = tenki_mapping.get(weather)
#オッズ
odds = cols[9].text.strip()
track_condition = cols[15].text.strip()
#馬場状態
baba_mapping = {'良': 0, '稍': 1, '重': 2, '不': 3}
track_condition = baba_mapping.get(track_condition)
result = [str_date,past_umaban,past_kishu,past_kinryo, odds, weight, weight_dif, up, through, order_of_finish, distance, race_rank, time, track, weather, track_condition]
results.append(result)
# 5行取得したら終了
if len(results) >= 5:
# 最終アウトプットに追加
# 横に連結
# resultsをnumpy配列に変換
results_array = np.array(results)
# numpy配列を1次元に変換
flattened_results = results_array.ravel()
all_results[index+1].extend(flattened_results)
break
# 最終ループを判定
if i == len(rows[1:]):
if results: # resultsが空でない場合
results_array = np.array(results)
flattened_results = results_array.ravel()
all_results[index+1].extend(flattened_results)
# convert list to DataFrame
df_all_results = pd.DataFrame(all_results)
df_all_results.columns = df_all_results.iloc[0] # 最初の行を列名として設定
df_all_results = df_all_results.drop(df_all_results.index[0]) # 最初の行を削除
# 斤量に関連する列を数値に変換し、変換できないデータはNaNにします。
kinryo_columns = ['斤量', '斤量1', '斤量2', '斤量3', '斤量4','斤量5']
for col in kinryo_columns:
df_all_results[col] = pd.to_numeric(df_all_results[col], errors='coerce')
# 平均斤量を計算します。
df_all_results['平均斤量'] = df_all_results[kinryo_columns].mean(axis=1)
# CSVファイルから騎手の勝率を読み込む
jockey_win_rate = pd.read_csv('calc_rate/jockey_win_rate.csv')
# 騎手ごとの勝率を取得して新たなデータフレームを作成
jockey_stats = jockey_win_rate.groupby('騎手')['騎手の勝率'].first().reset_index()
# df_combinedとjockey_statsを結合して騎手の勝率を代入する
df_all_results = df_all_results.merge(jockey_stats, on='騎手', how='left')
df_all_results["距離差"] = pd.to_numeric(df_all_results["距離"]) - pd.to_numeric(df_all_results["距離1"])
df_all_results["日付"] = df_all_results["日付"].map(str)
df_all_results["日付1"] = df_all_results["日付1"].map(str)
df_all_results["日付2"] = df_all_results["日付2"].map(str)
df_all_results["日付3"] = df_all_results["日付3"].map(str)
df_all_results["日付4"] = df_all_results["日付4"].map(str)
df_all_results["日付5"] = df_all_results["日付5"].map(str)
df_all_results["日付差"] = (pd.to_datetime(df_all_results["日付"], errors='coerce') - pd.to_datetime(df_all_results["日付1"], errors='coerce')).dt.days
df_all_results["距離差1"] = pd.to_numeric(df_all_results["距離1"]) - pd.to_numeric(df_all_results["距離2"])
df_all_results["日付差1"] = (pd.to_datetime(df_all_results["日付1"], errors='coerce') - pd.to_datetime(df_all_results["日付2"], errors='coerce')).dt.days
df_all_results["距離差2"] = pd.to_numeric(df_all_results["距離2"]) - pd.to_numeric(df_all_results["距離3"])
df_all_results["日付差2"] = (pd.to_datetime(df_all_results["日付2"], errors='coerce') - pd.to_datetime(df_all_results["日付3"], errors='coerce')).dt.days
df_all_results["距離差3"] = pd.to_numeric(df_all_results["距離3"]) - pd.to_numeric(df_all_results["距離4"])
df_all_results["日付差3"] = (pd.to_datetime(df_all_results["日付3"], errors='coerce') - pd.to_datetime(df_all_results["日付4"], errors='coerce')).dt.days
df_all_results["距離差4"] = pd.to_numeric(df_all_results["距離4"]) - pd.to_numeric(df_all_results["距離5"])
df_all_results["日付差4"] = (pd.to_datetime(df_all_results["日付4"], errors='coerce') - pd.to_datetime(df_all_results["日付5"], errors='coerce')).dt.days
# DataFrameを配列に変換
array_data = df_all_results.values
# カラム名を配列の先頭に挿入
columns = df_all_results.columns
all_results = np.insert(array_data, 0, columns, axis=0)
date_object = datetime.strptime(race_date, "%Y/%m/%d")
# 日付を指定のフォーマットに変換
formatted_date = date_object.strftime('%Y%m%d')
# データをCSVファイルに出力する
with open('race_data/race_data_' + racecourse + '_'+race_num+'R_' + formatted_date + '.csv', 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
for data in all_results:
writer.writerow(data)使い方
URLの指定
URLはすべてをコピーして貼り付けるのではなく、下2桁は排除してください。
下2桁はレース番号になるのですが、レース番号はループの中で生成しています。
main_page_url = "https://race.netkeiba.com/race/shutuba.html?race_id=2023040305"
start = 1
end = 13例の1から13にしておけば、すべてのレースを取得することが出来ます。
メインレースだけを取得したいのであれば、11から12と指定すれば1レースのみ取得できます。
対象外となるレース
上記のコードでは”新馬戦”と”2歳未勝利”のレースデータは取得されないようになっています。(40行目付近)
理由としては、過去5レースの結果が予測には重要なのですが、上記のようなレースでは過去データがないか少ないので十分な予測精度が出ません。
オッズと人気
オッズと人気もスクレイピングで取得していますが、「—」や「**」になっていると思います。
スクレイピングの技術的な制約により取得できません。(javascriptで生成された要素は取得できない仕様)
予想には使用していないので気にしなくて大丈夫です。
もし使いたい方はスクレイピングではなく、seleniumという技術を使えば取得できるようになります。
簡易的に取得したいのであれば以下のコードをchromeの開発者ツール(F12キーで開く)で以下のスクリプトを実行してください。
let result = '';
$('[id^="odds-1_"]').each(function() {
result += $(this).text() + '\n';
});
console.log(result);let result = '';
$('[id^="ninki-1_"]').each(function() {
result += $(this).text() + '\n';
});
console.log(result);実行
実行するには以下のコマンドをターミナルで打ち込んでください。
python race_table_scraping.py実行するとrace_dataフォルダにファイルが作成されます。
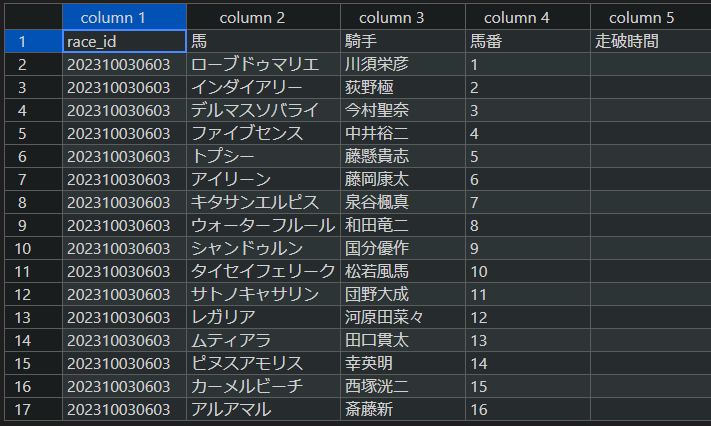
ファイルの中身はこのようになっているかと思います。
まとめ
いかがでしたでしょうか?
このプログラムさえあれば予想するレースデータの作成作業が短時間で済むようになります。
ここまで作成しても、おそらく精度や回収率は低いままだと思います。
次回以降は精度を上げるために特徴量を増やしていく方法を紹介したいと思います。
是非次回の記事もお楽しみにしてください。



コメント
お世話になっております。
上記コードで実行したところ、以下エラーが発生し、途中で停止してしまいます。
line 125, in
main_rows = table.find_all(“tr”)
AttributeError: ‘NoneType’ object has no attribute ‘find_all’
何か原因わかりますでしょうか?お忙しい中申し訳ございませんが、よろしくお願いいたします。
指定したURLが出馬表ではなく、「オッズ」や「結果」のページになっていませんか?
自分もたまにミスして指定してしまうことがあります。
# CSVファイルから騎手の勝率を読み込む
jockey_win_rate = pd.read_csv(‘calc_rate/jockey_win_rate.csv’)
個々の部分のコードでこのcsvファイルはいつ作りましたか?
エラーでこのファイルがないとなってしまいます、
競馬AI②のencode.pyです。
ちょうど昨日更新したので、差分を確認してみてください。
https://agusblog.net/keiba-ai-predict/#comment-59 でお返事頂きましてありがとうございました。
早速上記のコードを試しました。
https://race.netkeiba.com/race/shutuba.html?race_id=202307040211
の下二桁を消して
https://race.netkeiba.com/race/shutuba.html?race_id=2023070402
をmain_page_urlに代入したところ下記のエラーが出ました。
Traceback (most recent call last):
File “D:\Python\path\my_venv\HorseRace\race_table_scraping_new.py”, line 39, in
print(racename.text.strip())
AttributeError: ‘NoneType’ object has no attribute ‘text’
どこを修正すればエラーを解消できるかご教示頂けますでしょうか?お手数おかけしますがよろしくお願い致します。
ブログのコードをコピペして、提供いただいたURLで実行してみましたが、同様のエラーは出ませんでした。
エラーメッセージだけだと判断できませんが、「racename」が取得できていない→「soup.find(“div”, class_=”RaceName”)」が取れていない→BeautifulSoup(response.content, “html.parser”)が正常に動いていない
と考えると、スクレイピングでwebページに正常にアクセスできていない可能性があります。
気になる箇所にprintのコードを埋め込み、どこまで正しく動いていて、どこからおかしいのかチェックしてみてください。
大変申し訳ございません。今もう一度やり直してみたところ、ちゃんとcsvファイルが生成されました。
私の確認不足でコメントしてしまいすみませんでした🙇
引き続き勉強させて頂きます。ありがとうございます。
お世話になります
コード入力したらエラーが発生しました
Traceback (most recent call last):
File “c:\Users\user\作業python\race_table_scraping4.py”, line 140, in
url2 = a_tag2.get(‘href’)
^^^^^^^^^^
AttributeError: ‘NoneType’ object has no attribute ‘get’
URLは
main_page_url = “https://race.netkeiba.com/race/shutuba.html?race_id=2024060101”
start = 11
end = 12
です。レース名は取得してる感じです
お手数おかけしますがよろしくお願い致します。
騎手名を取得するところでエラーとなっているようです。
私の方ではエラーが出ないので、もしかすると昨日時点では騎手が確定していなかったとかではないでしょうか?
再度取得を試してみてください。
返信ありがとうございます。
そうですね。朝してみたらできました。確定していなかったようです。
ありがとうございます。
引き続き勉強させてもらいます。
こんばんは。試しに3/16の中山レースを実施し、csvを出力したところ、斤量や日付差などnoneや空白ばかりになっています。(半分は正常に取得できてる模様)
どの段階(データ加工?)でミスってるのでしょうか。。
対象の馬が過去1,2レースしかしていない場合は空白になってしまいます。
新馬戦であれば、過去のデータはすべて空白です。
まずは実際の馬の情報と照らし合わせてみてください。
いつも参考にさせて貰っています。
先週からracenameの取得が上手くいかず
File “c:\Users\user\keiba\date_scraping.py”,line 40, inprint(racename.text.strip())
AttributeError: ‘NoneType’ object has no attribute ‘text’を繰り返しています。
このページのコードをコピペ&テストしても同じエラーのままです。
どうしたらいいでしょうか。
私も同様のエラーが出ました。
ページの構成が変わったようです。
divからh1に変更すれば動きます。
下記コードを参考にしてください。
soup.find(“h1″, class_=”RaceName”)
ありがとうございます。
無事にデータを取得する事が出来ました。
引き続き勉強させて貰います。
レース数を増やして取得することはできますか その場合プログラムのどの部分を変更すればいいですか
23,24行目のstart,endの数値を1,13にすれば、12レース分すべて取得できるようになります!
以前まで動いていたのですが天皇賞・春の予想を行おうとすると
下記のエラーが出力されるのですが、出走取消が影響しているというところでしょうか?
AttributeError: ‘NoneType’ object has no attribute ‘text’
ページの構成が変わったようです。
divからh1に変更すれば動きます。
下記コードを参考にしてください。
soup.find(“h1″, class_=”RaceName”)
コメント失礼します。既に上にありますが同じエラーが出ます。
Traceback (most recent call last):
File “c:\Users\yumik\keiba\race_table_scraping.py”, line 41, in
print(racename.text.strip())
^^^^^^^^^^^^^
AttributeError: ‘NoneType’ object has no attribute ‘text’
何度もやり直しているんですがこの先に進めません。
racenameがnoneになってしまいます。
改善方法があれば教えていただけませんでしょうか?
racename = soup.find(“h1″, class_=”RaceName”)
38行目のこの修正で直りませんでしたか?
記事本文も修正しておきます。
ありがとうございました。
動くようになりました。
start = 11
end = 12
は何を表しているのでしょうか?予想するレースを指定しているのでしょうか?例えば、第3Rの予想をしたければstart=3, end=4になるということでしょうか?ご教示お願いします。
その通りです。
1R~12Rすべてを取得したければ、start=1, end=13と指定します。
ありがとうございました!
いつもお世話になっております。
初歩的な質問で申し訳ないのですが、馬場情報をスクレイピングし実際の予測する特徴量として活用したいのですが、どのようなコードを追加すれば取得できるのでしょうか?
お手すきの際にご教示いただけたら幸いです。よろしくお願いいたします。
babaSpan = soup.find(“span”, class_=”Item04″)のところですが、馬場の情報があるclassがItem04だったり、Item03だったりするようです。規則性は無いように思います。。結果にどれくらい影響あるか分かりませんが報告します。
Pythonおよび機械学習の勉強がてら参考にさせていただいております。
いつも興味深い内容ありがとうございます。
漸く自分なりの特徴量を組み込むことができるようになりました。
この際クラスの値を使って特徴量を計算したいと思って変更していましたが、
mappings = {‘障害’:0, ‘G1’, ….
の箇所ではG1-G3のクラスが定義された値ではなく、すべて0になってしまいました。
HTMLのソースを確認した所、G1-3はGI, GII, GIIIの表記に変更?となっているようで、このためマッチせずに以下のreturn 0 で0が返って来ているようです。
for key, value in mappings.items():
if key in row:
return value
return 0 # If no mapping is found, return 0
G1-3に加えGI-IIIを追加しましたが、GIを先にするとGIIIもGIと判断されるようで、GIII、GII、GIの順で定義しなおしましたが、すべてレース名のGIII部分を部分的に完全マッチさせる方法があればGIからの順番にできるのかと思いましたが、そのような方法はあるのでしょうか?
key == row
ですとkeyつまりレース名に完全マッチするように動く様です。。。。
またこのクラスに割り当てている値は整数でないとまずいのでしょうか?
初歩的な質問で申し訳ありません。お時間あればアドバイスください。
確かに0になって返ってきますね。
気づいていませんでした。ありがとうございます。
GIII~GIの順番に直して正しく動いているのであれば問題ありません!
整数である必要もないので、動けばOKです!
前走が海外で欠損値がある場合、どこかでデータを拾ってくるなどの対策はしていますか?
対策してるのでしたら、もしよろしければどこから拾っているのかなど教えて頂けたら幸いです。
欠損値の対策はしておりません。
netkeiba以外からの取得はしていません。
お世話になっております。
こちらのコードを実行すると
AttributeError: ‘NoneType’ object has no attribute ‘text’
とエラーが出てしまうのですがページの構成が変わってしまったのですかね?
改善方法があれば教えて頂けると幸いです。
netkeibaの方でクローラー対策が行われたそうです。
アクセス頻度が高いと引っかかってしまうそうです。
私もダメになりました。
Seleniumという技術を使うと回避が出来ます。
以下サンプルコードです。適切な箇所に設定してみてください。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
# WebDriverの設定
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get(url)
soup = BeautifulSoup(driver.page_source, ‘html.parser’)
これより以下は同じコードで動きます。
お世話になります。
今週またracenameの取得が上手く行かなくなりました。
以前(半年ほど前?)の時はページの構成が変わったとのことで
下記のコード
soup.find(“h1″, class_=”RaceName”)
の”h1″の部分を変える修正をされたかと思いますが、
今回も同様にページの構成が変わったことによるエラーになるのでしょうか?
仮に同様のエラーだとすると”h1″から修正する必要がありそうですが
どのように変更すれば良いのでしょうか?
また可能でしたらページ変更時のこの”h1″の部分が自分で確認出来れば
今後同様のエラーが出た時に自分で調べて対処出来そうですが
確認方法がありましたらご教授頂けますと幸いです。
以上よろしくお願い致します。
netkeibaの方でクローラー対策が行われたそうです。
アクセス頻度が高いと引っかかってしまうそうです。
私もダメになりました。
Seleniumという技術を使うと回避が出来ます。
以下サンプルコードです。適切な箇所に設定してみてください。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
# WebDriverの設定
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get(url)
soup = BeautifulSoup(driver.page_source, ‘html.parser’)
これより以下は同じコードで動きます。
既出のエラーですが,
Traceback (most recent call last):
File “C:\Users\FMV\OneDrive\デスクトップ\Racing\Python\race_table_scraping.py”, line 38, in
print(racename.text.strip())
^^^^^^^^^^^^^
AttributeError: ‘NoneType’ object has no attribute ‘text’
が表示されます.過去に問題となっていた racename = soup.find(“h1″, class_=”RaceName”)の部分はh1となっています
netkeibaの方でクローラー対策が行われたそうです。
アクセス頻度が高いと引っかかってしまうそうです。
私もダメになりました。
Seleniumという技術を使うと回避が出来ます。
以下サンプルコードです。適切な箇所に設定してみてください。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
# WebDriverの設定
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get(url)
soup = BeautifulSoup(driver.page_source, ‘html.parser’)
これより以下は同じコードで動きます。
本日netkeibaのhtml構造が変更されたのでしょうか。
エラーが多発して、スクレイピングができない状況です。
netkeibaの方でクローラー対策が行われたそうです。
アクセス頻度が高いと引っかかってしまうそうです。
私もダメになりました。
Seleniumという技術を使うと回避が出来ます。
以下サンプルコードです。適切な箇所に設定してみてください。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
# WebDriverの設定
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get(url)
soup = BeautifulSoup(driver.page_source, ‘html.parser’)
これより以下は同じコードで動きます。
print(racename.text.strip())
AttributeError: ‘NoneType’ object has no attribute ‘text’
上のコードで急にこのようなエラーが出ていまいました。以前までは使うことができました。
netkeibaの方でクローラー対策が行われたそうです。
アクセス頻度が高いと引っかかってしまうそうです。
私もダメになりました。
Seleniumという技術を使うと回避が出来ます。
以下サンプルコードです。適切な箇所に設定してみてください。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
# WebDriverの設定
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get(url)
soup = BeautifulSoup(driver.page_source, ‘html.parser’)
これより以下は同じコードで動きます。
クルーミング対策でスクレイピングできなくなったようです。上記の回答でもサンプルコードが載っていますがプログラミング初心者なので、調べつつ実装しても動かなかったです。h1_element = element2.find(‘h1’)
AttributeError: ‘NoneType’ object has no attribute ‘find’
というエラーが起きます。ページの構成が変わったのでしょうか?それとも実装の仕方が悪かったのでしょうか?具体的にどの位置にどのようなコードを配置すればよいのか教えていただけたら幸いです。よろしくお願い致します。
クローラー対策でした。すみません
対策のコードを記載した記事を公開しました。
確認してみてください。
ありがとうございます。無事に動きました。
当日の体重はレース直前にならないと分からないですが直前に予想していますか?
私は前日に予想してしまうので、体重は含めていません。
そういった方は学習データからも外した方が良いと思います。