
こちらの記事は旧AI開発の記事になっております。netkeibaの対策により現在はスクレイピングが禁止されております。
新しい競馬AIの記事はこちらからになります!ぜひ読んでみてください。

前回からの続きの記事になります。

前回は過去のレースデータを学習させてモデルを作成しました。
今回はそのモデルを使用し、実際のレースで予想をしていきます。
予想するレースデータの準備
作成するデータのヘッダー情報
ヘッダーは以下の通りです。出走する馬の数だけ行を作成する必要があります。
1~2行目が対象レースの情報、3行目の「日付1」からが過去レースの情報になります。
race_id,馬,騎手,馬番,走破時間,オッズ,通過順,着順,体重,体重変化,性,齢,斤量,上がり,人気,レース名,日付,開催,クラス,芝・ダート,距離,回り,馬場,天気,場id,場名,距離差,日付差,
日付1,馬番1,騎手1,斤量1,オッズ1,体重1,体重変化1,上がり1,通過順1,着順1,距離1,クラス1,走破時間1,芝・ダート1,天気1,馬場1,距離差1,日付差1,日付2,馬番2,騎手2,斤量2,オッズ2,体重2,体重変化2,上がり2,通過順2,着順2,距離2,クラス2,走破時間2,芝・ダート2,天気2,馬場2,距離差2,日付差2,日付3,馬番3,騎手3,斤量3,オッズ3,体重3,体重変化3,上がり3,通過順3,着順3,距離3,クラス3,走破時間3,芝・ダート3,天気3,馬場3,距離差3,日付差3,日付4,馬番4,騎手4,斤量4,オッズ4,体重4,体重変化4,上がり4,通過順4,着順4,距離4,クラス4,走破時間4,芝・ダート4,天気4,馬場4,距離差4,日付差4,日付5,馬番5,騎手5,斤量5,オッズ5,体重5,体重変化5,上がり5,通過順5,着順5,距離5,クラス5,走破時間5,芝・ダート5,天気5,馬場5※2023/7/11更新
馬番,騎手,斤量を過去レースデータそれぞれに追加
対象レースを選ぶ
netkeibaのサイトで対象レースを開いてください。
以下の情報をこの画面を参照し入力していきます。
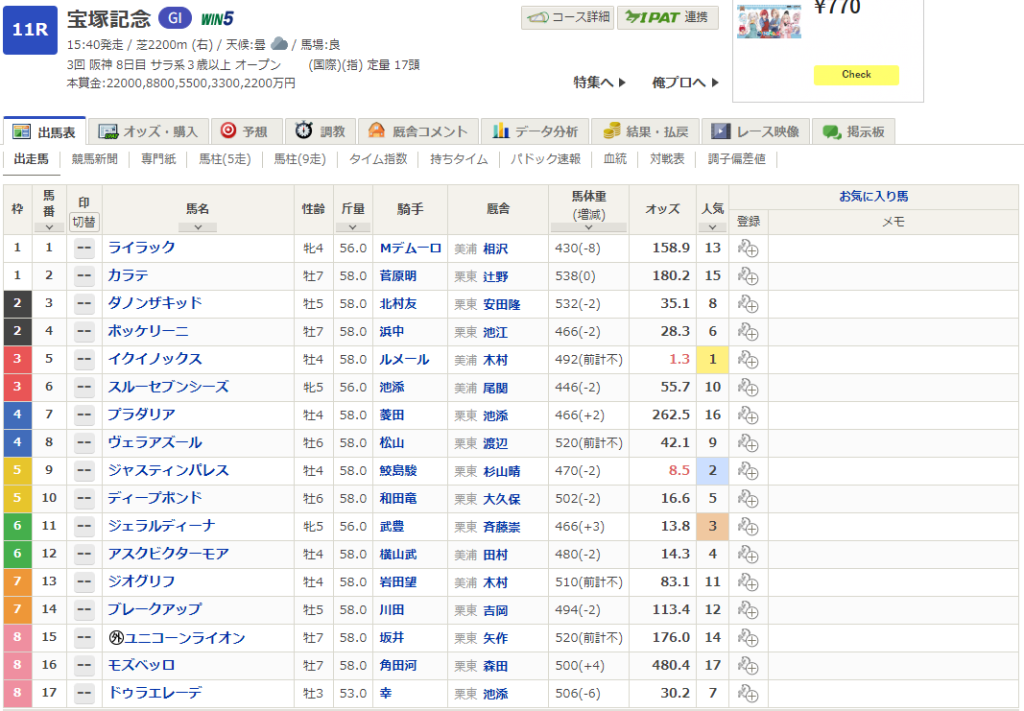
性、クラス、芝・ダート、回り、馬場、天気、場idなどは、前回までのプログラムを確認し、数字に書き換えてください。
編集はExcelかスプレッドシートがやりやすいです!
race_id,馬,騎手,馬番,走破時間,オッズ,通過順,着順,体重,体重変化,性,齢,斤量,上がり,人気,レース名,日付,開催,クラス,芝・ダート,距離,回り,馬場,天気,場id,場名過去5走のデータを追加する
次に馬ごとの過去5走のデータを取得します。
馬の詳細画面を開き、以下の情報を入れていきます。
距離差,日付差,日付1,馬番1,騎手1,斤量1,オッズ1,体重1,体重変化1,上がり1,通過順1,着順1,距離1,クラス1,走破時間1,芝・ダート1,天気1,馬場1,距離差1,日付差1,日付2,馬番2,騎手2,斤量2,オッズ2,体重2,体重変化2,上がり2,通過順2,着順2,距離2,クラス2,走破時間2,芝・ダート2,天気2,馬場2,距離差2,日付差2,日付3,馬番3,騎手3,斤量3,オッズ3,体重3,体重変化3,上がり3,通過順3,着順3,距離3,クラス3,走破時間3,芝・ダート3,天気3,馬場3,距離差3,日付差3,日付4,馬番4,騎手4,斤量4,オッズ4,体重4,体重変化4,上がり4,通過順4,着順4,距離4,クラス4,走破時間4,芝・ダート4,天気4,馬場4,距離差4,日付差4,日付5,馬番5,騎手5,斤量5,オッズ5,体重5,体重変化5,上がり5,通過順5,着順5,距離5,クラス5,走破時間5,芝・ダート5,天気5,馬場5ここは手作業でデータを作成するとかなりの時間がかかってしまうので、スクレイピングで取得するプログラムを作成したので使ってください。
url_listをそれぞれの馬の詳細画面のURLで書き換えて実行すると、csvデータが作成されるので、日付1以降に貼り付けてください。
from bs4 import BeautifulSoup
import requests
from datetime import datetime
import numpy as np
import csv
def class_mapping(row):
mappings = {'障害':0, 'G1': 10, 'G2': 9, 'G3': 8, '(L)': 7, 'オープン': 7, '3勝': 6, '1600': 6, '2勝': 5, '1000': 5, '1勝': 4, '500': 4, '新馬': 3, '未勝利': 1}
for key, value in mappings.items():
if key in row:
return value
return 0 # If no mapping is found, return 0
url_list = [
"https://db.netkeiba.com/horse/2019103588",
"https://db.netkeiba.com/horse/2016106606",
"https://db.netkeiba.com/horse/2018104963",
"https://db.netkeiba.com/horse/2016104618",
"https://db.netkeiba.com/horse/2019105219",
"https://db.netkeiba.com/horse/2018105269",
"https://db.netkeiba.com/horse/2019100109",
"https://db.netkeiba.com/horse/2017105082",
"https://db.netkeiba.com/horse/2019105346",
"https://db.netkeiba.com/horse/2017102170",
"https://db.netkeiba.com/horse/2018105081",
"https://db.netkeiba.com/horse/2019104706",
"https://db.netkeiba.com/horse/2019105056",
"https://db.netkeiba.com/horse/2018106273",
"https://db.netkeiba.com/horse/2016110103",
"https://db.netkeiba.com/horse/2016100915",
"https://db.netkeiba.com/horse/2020103626"
] # スクレイピングしたいURLを指定
all_results = [] # 全てレース結果を保存するためのリスト
# cutoff_date = datetime.strptime('2023/05/27', '%Y/%m/%d') # 特定の日付を指定
# 現在の日付を取得
now = datetime.now()
# cutoff_date を datetime 型に変換
cutoff_date = datetime.strptime(now.strftime('%Y/%m/%d'), '%Y/%m/%d')
for url in url_list:
results = [] # 馬単位のレース結果を保存するためのリスト
response = requests.get(url)
# ステータスコードが200以外の場合はエラーが発生したとみなし、処理をスキップ
if response.status_code != 200:
print(f"Error occurred while fetching data from {url}")
continue
soup = BeautifulSoup(response.content, "html.parser")
# テーブルを指定
table = soup.find("table", {"class": "db_h_race_results nk_tb_common"})
# テーブル内の全ての行を取得
rows = table.find_all("tr")
# 各行から必要な情報を取り出し
for i, row in enumerate(rows[1:], start=1):# ヘッダ行をスキップ
cols = row.find_all("td")
# 日付を解析
str_date = cols[0].text.strip()
date = datetime.strptime(str_date, '%Y/%m/%d')
# 特定の日付より前のデータのみを取得
if date < cutoff_date:
# 取得したいデータの位置を指定し取得
#体重
horse_weight = cols[23].text.strip()
weight = 0
weight_dif = 0
try:
weight = int(horse_weight.split("(")[0])
weight_dif = int(horse_weight.split("(")[1][0:-1])
except:
weight = ''
weight_dif = ''
weight = weight
weight_dif = weight_dif
#上がり
up = cols[22].text.strip()
#通過順
through = cols[20].text.strip()
try:
numbers = list(map(int, through.split('-')))
through = sum(numbers) / len(numbers)
except ValueError:
through = ''
#着順
order_of_finish = cols[11].text.strip()
try:
order_of_finish = str(int(order_of_finish))
except ValueError:
order_of_finish = ""
#馬番
past_umaban = cols[8].text.strip()
#騎手
past_kishu = cols[12].text.strip()
#斤量
past_kinryo = cols[13].text.strip()
#距離
distance = cols[14].text.strip()
#芝・ダート
track = distance[0]
shiba_mapping = {'芝': 0, 'ダ': 1, '障': 2}
track = shiba_mapping.get(track)
#距離
distance = distance[1:]
#レース名
race_name = cols[4].text.strip()
race_rank = class_mapping(race_name)
#タイム
time = cols[17].text.strip()
try:
time = float(time.split(':')[0]) * 60 + sum(float(x) / 10**i for i, x in enumerate(time.split(':')[1].split('.')))
except:
time = ''
#天気
weather = cols[2].text.strip()
tenki_mapping = {'晴': 0, '曇': 1, '小': 2, '雨': 3, '雪': 4}
weather = tenki_mapping.get(weather)
#オッズ
odds = cols[9].text.strip()
track_condition = cols[15].text.strip()
#馬場状態
baba_mapping = {'良': 0, '稍': 1, '重': 2, '不': 3}
track_condition = baba_mapping.get(track_condition)
result = [str_date,past_umaban,past_kishu,past_kinryo, odds, weight, weight_dif, up, through, order_of_finish, distance, race_rank, time, track, weather, track_condition,"",""]
results.append(result)
# 5行取得したら終了
if len(results) >= 5:
# 最終アウトプットに追加
# 横に連結
# resultsをnumpy配列に変換
results_array = np.array(results)
# numpy配列を1次元に変換
flattened_results = results_array.ravel()
all_results.append(flattened_results)
break
# 最終ループを判定
if i == len(rows[1:]):
if results: # resultsが空でない場合
results_array = np.array(results)
flattened_results = results_array.ravel()
all_results.append(flattened_results)
# データをCSVファイルに出力する
with open('race_data/t_data.csv', 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
for data in all_results:
writer.writerow(data)
※2023/7/11更新
馬番,騎手,斤量の追加対応
距離差、日付差は自動で入らないので関数を使って計算してください。
スプレッドシートに貼り付ける場合は以下のように「テキストを列に分割」を選択すると各セルに貼り付けることが出来ます。
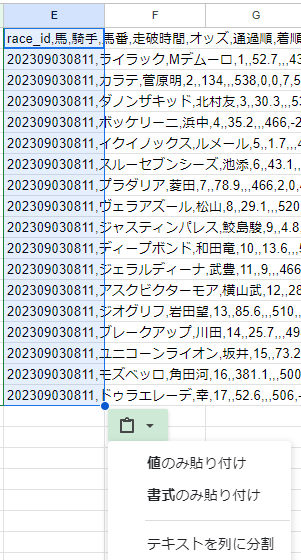
サンプルデータ
2023/6/25に実施された宝塚記念のデータを添付しているので試してみてください。
もし文字化けしていたら、テキストエディタで開きSJISに変更して保存しなおしてみてください。
予想する
コード
以下のコードをコピーして新しいファイルを作成してください。
※複数ファイルを一度に予想するコードもこのページの最後に記載したので、そちらもご確認ください。
import pandas as pd
import lightgbm as lgb
from sklearn.preprocessing import LabelEncoder, StandardScaler
yearStart = 2005
yearEnd = 2022
# 予測を行う新しいデータの読み込み
file_name = '予想したいレースのファイル名'
new_data = pd.read_csv('race_data/' + file_name + '.csv')
#人気、オッズを退避
pop = new_data['人気']
odds = new_data['オッズ']
# 着順列を除外 (この列が存在する場合)
new_data = new_data.drop(['着順','オッズ','人気','上がり','走破時間','通過順'], axis=1)
#日付
# 日付時刻型への変換を試み、無効な形式であればNaNにする
new_data['日付'] = pd.to_datetime(new_data['日付'], errors='coerce')
new_data['日付1'] = pd.to_datetime(new_data['日付1'], errors='coerce')
new_data['日付2'] = pd.to_datetime(new_data['日付2'], errors='coerce')
new_data['日付3'] = pd.to_datetime(new_data['日付3'], errors='coerce')
new_data['日付4'] = pd.to_datetime(new_data['日付4'], errors='coerce')
new_data['日付5'] = pd.to_datetime(new_data['日付5'], errors='coerce')
# 日付カラムから年、月、日を抽出
new_data['year'] = new_data['日付'].dt.year
new_data['month'] = new_data['日付'].dt.month
new_data['day'] = new_data['日付'].dt.day
# (年-yearStart)*365 + 月*30 + 日 を計算し新たな '日付'カラムを作成
new_data['日付'] = (new_data['year'] - yearStart) * 365 + new_data['month'] * 30 + new_data['day']
new_data['year'] = new_data['日付1'].dt.year
new_data['month'] = new_data['日付1'].dt.month
new_data['day'] = new_data['日付1'].dt.day
# (年-yearStart)*365 + 月*30 + 日 を計算し新たな '日付'カラムを作成
new_data['日付1'] = (new_data['year'] - yearStart) * 365 + new_data['month'] * 30 + new_data['day']
new_data['year'] = new_data['日付2'].dt.year
new_data['month'] = new_data['日付2'].dt.month
new_data['day'] = new_data['日付2'].dt.day
# (年-yearStart)*365 + 月*30 + 日 を計算し新たな '日付'カラムを作成
new_data['日付2'] = (new_data['year'] - yearStart) * 365 + new_data['month'] * 30 + new_data['day']
new_data['year'] = new_data['日付3'].dt.year
new_data['month'] = new_data['日付3'].dt.month
new_data['day'] = new_data['日付3'].dt.day
# (年-yearStart)*365 + 月*30 + 日 を計算し新たな '日付'カラムを作成
new_data['日付3'] = (new_data['year'] - yearStart) * 365 + new_data['month'] * 30 + new_data['day']
new_data['year'] = new_data['日付4'].dt.year
new_data['month'] = new_data['日付4'].dt.month
new_data['day'] = new_data['日付4'].dt.day
# (年-yearStart)*365 + 月*30 + 日 を計算し新たな '日付'カラムを作成
new_data['日付4'] = (new_data['year'] - yearStart) * 365 + new_data['month'] * 30 + new_data['day']
new_data['year'] = new_data['日付5'].dt.year
new_data['month'] = new_data['日付5'].dt.month
new_data['day'] = new_data['日付5'].dt.day
# (年-yearStart)*365 + 月*30 + 日 を計算し新たな '日付'カラムを作成
new_data['日付5'] = (new_data['year'] - yearStart) * 365 + new_data['month'] * 30 + new_data['day']
# 不要となった 'year', 'month', 'day' カラムを削除
new_data.drop(['year', 'month', 'day'], axis=1, inplace=True)
# カテゴリカル変数のエンコーディング
categorical_features = ['馬', '騎手', 'レース名','場名','開催', '騎手1', '騎手2', '騎手3', '騎手4', '騎手5'] # カテゴリカル変数の列名を指定してください
# ラベルエンコーディング
for i, feature in enumerate(categorical_features):
print(f"\rProcessing feature {i+1}/{len(categorical_features)}", end="")
le = LabelEncoder()
new_data[feature] = le.fit_transform(new_data[feature])
# モデルの読み込み
model = lgb.Booster(model_file='model/model.txt')
# Make prediction
y_new_pred = model.predict(new_data)
# 予測結果を0と1に変換
# y_new_pred = (y_new_pred >= 0.5).astype(int)
# 予測結果の表示
print(y_new_pred)
# '予測結果'という新しい列を2列目に追加
new_data.insert(1, '予測結果', y_new_pred)
new_data.insert(3, '人気', pop)
new_data.insert(4, 'オッズ', odds)
# Save prediction
new_data.to_csv('predict_result/' + file_name + '.csv', index=False)
※2023/7/11修正
特徴量の追加や削除
もしエラーが出るのであればコメントください。
実行
※「race_data」フォルダを作成し、予想するデータファイルを格納してください。
実行するには以下のコマンドをターミナルで打ち込んでください。
python predict.py実行すると、予想に使ったファイルに列が追加されます。
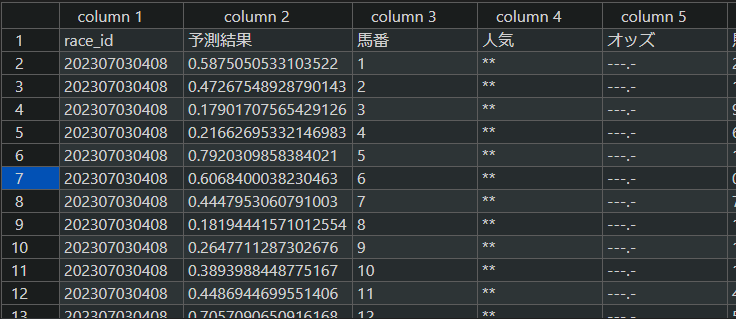
予測結果の値が大きいほど上位に来るという予想になります。
予想結果の確認
今回は宝塚記念の予想をしてみました。
分かりやすいように馬列と着順列を追加しています。
予測結果列でソートすると上位予想が確認できます。
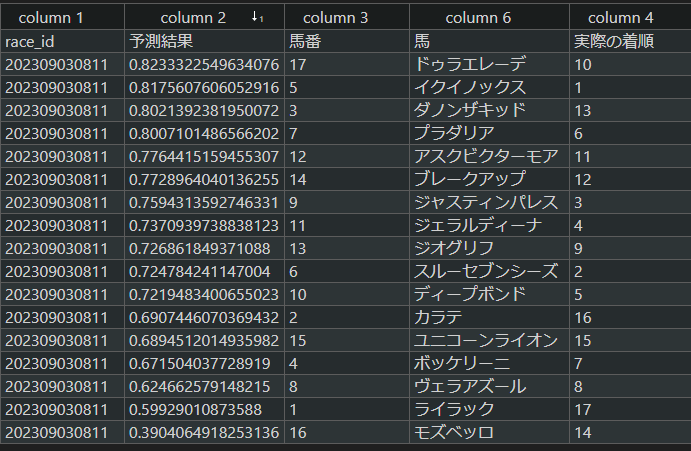
予想結果はいかがでしょうか?
上位予想の中ではイクイノックスだけが当たりという結果でした。
1レースだけでは収束はしないので長期的に確認する必要があります。
※もし結果が異なっていたらすみません。いろいろパラメータをいじっていたので違うモデルを使った可能性があります。
まとめ
今回は予想するデータの作成と、作成したモデルを使用して実際のレースの予測を行っていきました。
予測結果は今回は良い精度が出ましたが、必ずしも良い結果が出るとは限らないので、
「予想→結果を確認→パラメータを修正→モデルを作り直し」を繰り返していきます。
モデルの改良はLightGBMについて理解する必要があります。以下の書籍がおススメです。

良いモデルを作成して、AI競馬予想を楽しんでください!
もう少しデータ作成しやすくなるように改良したら紹介します。
作ったモデルを使って、過去データから回収率などを計算できないか試してみます。
【追記 2024/1/18】複数ファイルを一度に予想する
ループで一度に予測できるように修正しました。ファイルパスなどは環境に合わせて修正してください。
import pandas as pd
import lightgbm as lgb
from sklearn.preprocessing import LabelEncoder
import os
yearStart = 2005
# フォルダのパス
dir_path = "race_data"
# フォルダ内のすべてのファイルとディレクトリを取得
all_items = os.listdir(dir_path)
# フォルダを除外して、ファイルのみのリストを作成
file_list = [item for item in all_items if os.path.isfile(os.path.join(dir_path, item))]
for path in file_list:
# 予測を行う新しいデータの読み込み
new_data = pd.read_csv('race_data/' + path)
# 着順列を除外 (この列が存在する場合)
new_data = new_data.drop(['着順','オッズ','人気','上がり','走破時間','通過順'], axis=1)
#日付
# 日付時刻型への変換を試み、無効な形式であればNaNにする
new_data['日付'] = pd.to_datetime(new_data['日付'], errors='coerce')
new_data['日付1'] = pd.to_datetime(new_data['日付1'], errors='coerce')
new_data['日付2'] = pd.to_datetime(new_data['日付2'], errors='coerce')
new_data['日付3'] = pd.to_datetime(new_data['日付3'], errors='coerce')
new_data['日付4'] = pd.to_datetime(new_data['日付4'], errors='coerce')
new_data['日付5'] = pd.to_datetime(new_data['日付5'], errors='coerce')
# 日付カラムから年、月、日を抽出
new_data['year'] = new_data['日付'].dt.year
new_data['month'] = new_data['日付'].dt.month
new_data['day'] = new_data['日付'].dt.day
# (年-yearStart)*365 + 月*30 + 日 を計算し新たな '日付'カラムを作成
new_data['日付'] = (new_data['year'] - yearStart) * 365 + new_data['month'] * 30 + new_data['day']
new_data['year'] = new_data['日付1'].dt.year
new_data['month'] = new_data['日付1'].dt.month
new_data['day'] = new_data['日付1'].dt.day
new_data['日付1'] = (new_data['year'] - yearStart) * 365 + new_data['month'] * 30 + new_data['day']
new_data['year'] = new_data['日付2'].dt.year
new_data['month'] = new_data['日付2'].dt.month
new_data['day'] = new_data['日付2'].dt.day
new_data['日付2'] = (new_data['year'] - yearStart) * 365 + new_data['month'] * 30 + new_data['day']
new_data['year'] = new_data['日付3'].dt.year
new_data['month'] = new_data['日付3'].dt.month
new_data['day'] = new_data['日付3'].dt.day
new_data['日付3'] = (new_data['year'] - yearStart) * 365 + new_data['month'] * 30 + new_data['day']
new_data['year'] = new_data['日付4'].dt.year
new_data['month'] = new_data['日付4'].dt.month
new_data['day'] = new_data['日付4'].dt.day
new_data['日付4'] = (new_data['year'] - yearStart) * 365 + new_data['month'] * 30 + new_data['day']
new_data['year'] = new_data['日付5'].dt.year
new_data['month'] = new_data['日付5'].dt.month
new_data['day'] = new_data['日付5'].dt.day
new_data['日付5'] = (new_data['year'] - yearStart) * 365 + new_data['month'] * 30 + new_data['day']
# 不要となった 'year', 'month', 'day' カラムを削除
new_data.drop(['year', 'month', 'day'], axis=1, inplace=True)
# カテゴリカル変数のエンコーディング
categorical_features = ['馬', '騎手', 'レース名','場名','開催', '騎手1', '騎手2', '騎手3', '騎手4', '騎手5'] # カテゴリカル変数の列名を指定してください
# ラベルエンコーディング
for i, feature in enumerate(categorical_features):
print(f"\rProcessing feature {i+1}/{len(categorical_features)}", end="")
le = LabelEncoder()
new_data[feature] = le.fit_transform(new_data[feature])
# モデルの読み込み
model = lgb.Booster(model_file='model/model.txt')
# Make prediction
y_new_pred = model.predict(new_data)
# '予測結果'という新しい列を2列目に追加
new_data.insert(1, '予測結果', y_new_pred)
# Save prediction
new_data.to_csv('predict_result/' + path + '.csv', index=False)予想した結果はこちらで公開中!



コメント
yearStartとEndは自分がスクレイピングした年に変更すればいいのでしょうか。
yearStartとEndは何でも大丈夫です。
そもそもEndは使っていないですね。。
整理できていなくてすみません。
yearStartは日付型を数値変換するための変数として使っているだけです。
お世話になっております。目次の「2.対象レースを選ぶ」のところでは、基本的にサイトを見ながら馬名などを手入力していくイメージでしょうか?
添付データと同じような形式で、手入力していくイメージになります。
手入力は大変なので、自動で取得するコードも後に公開しているので参考にしてみてください。
いつもありがとうございます。参考にさせて頂いています。
「距離差、日付差は自動で入らないので関数を使って計算してください。」と記載がありますがどういう風にすれば良いでしょうか?
また、今回まだ開催されていないチャンピオンズC(https://race.netkeiba.com/race/shutuba.html?race_id=202307040211)を選んだのですが、race_table_scrapying.pyで作ったデータ内のrace_idと馬番が、1つ過去の試合の日付と馬番が出てきており、race_idの場所の数字も2023/11/03のような表記になっています。どうすれば良いでしょうか?
よろしくお願い致します。
「距離差、日付差は自動で入らないので関数を使って計算してください。」と記載がありますがどういう風にすれば良いでしょうか?
>例えばレモンポップの場合、チャンピオンCが12/3で前走が10/9なので、差は「55日」となります。 距離は1800mで前走は1600mなので差は「200」となります。
手作業でデータを作成するのは大変なので、「【競馬AI⑥】ほぼコピペだけ!予想するレースデータの作成を簡単にする方法を紹介」の記事を参考に、
スクレイピングのコードをアップデートしてみてください。
いつも拝見させていただいております。
一つご教授ください。
競馬AI⑥で作成されたコードを仕様してスクレイピングを行いました。
そのデータを元に競馬AI④の予想コードを仕様すると
どうしても
“馬”と”騎手名”が数字に変換されてしまいます。
何か対策出来る方法はありますでしょうか。
よろしくお願いいたします。
馬と騎手名は数字に変換しないと学習に掛けられないのであえて変換しています。
日本語にしたいのであれば、人気やオッズと同じように退避して戻すと日本語のまま残すことが出来ます。
いつも参考にさせていただいております。アップされている去年の宝塚記念のデータを使用して動かしたところ、
lightgbm.basic.LightGBMError: The number of features in data (110) is not the same as it was in training data (112).
というエラーが出ました。modelのほうもコピペして使用しています。
特徴量の違いからエラーを出されているのはわかるのですが、どうしたらいいのかわからないので教えていただきたいです。よろしくお願いします。
競馬AI②のencodeのコードで平均斤量と騎手の勝率を追加しているためのエラーだと思います。
サンプルデータにその2つの特徴量が入っていないためになります。
encodeの際にその2つの特徴量の部分をコメントアウトするか、サンプルデータに追加するかです。
または競馬AI⑥の記事まで進んでいただき、そのコードでデータを作成すれば動くと思います。
いつもありがとうございます。⑥のデータ生成を用いて動かしているのですが、実行結果の表で馬番がぐちゃぐちゃに並んでいて、馬番に0が発生していたり、元のデータと見比べて予測結果と馬番とそれ以外のデータがそれぞれズレているように思います。
実際は実行結果は1から昇順に並ぶのでしょうか?結果がずれてしまうのはどうしたらいいのでしょうか…。
実行結果は1から昇順に並びます。
⑥のコード実行しましたが正常に動いていました。
それでも結果がずれる場合は、デバッグしながらずれている箇所を特定するしかないかと思います。
{
“name”: “KeyError”,
“message”: “‘人気'”,
“stack”: “—————————————————————————
KeyError Traceback (most recent call last)
File c:\\Users\\Kimikatsu Hiraka\\Notebook\\.venv\\Lib\\site-packages\\pandas\\core\\indexes\\base.py:3805, in Index.get_loc(self, key)
3804 try:
-> 3805 return self._engine.get_loc(casted_key)
3806 except KeyError as err:
File index.pyx:167, in pandas._libs.index.IndexEngine.get_loc()
File index.pyx:196, in pandas._libs.index.IndexEngine.get_loc()
File pandas\\\\_libs\\\\hashtable_class_helper.pxi:7081, in pandas._libs.hashtable.PyObjectHashTable.get_item()
File pandas\\\\_libs\\\\hashtable_class_helper.pxi:7089, in pandas._libs.hashtable.PyObjectHashTable.get_item()
KeyError: ‘人気’
The above exception was the direct cause of the following exception:
KeyError Traceback (most recent call last)
Cell In[7], line 13
10 new_data = pd.read_csv(‘race_data/’ + file_name + ‘.csv’)
12 #人気、オッズを退避
—> 13 pop = new_data[‘人気’]
14 odds = new_data[‘オッズ’]
15 # 着順列を除外 (この列が存在する場合)
File c:\\Users\\Kimikatsu Hiraka\\Notebook\\.venv\\Lib\\site-packages\\pandas\\core\\frame.py:4090, in DataFrame.__getitem__(self, key)
4088 if self.columns.nlevels > 1:
4089 return self._getitem_multilevel(key)
-> 4090 indexer = self.columns.get_loc(key)
4091 if is_integer(indexer):
4092 indexer = [indexer]
File c:\\Users\\Kimikatsu Hiraka\\Notebook\\.venv\\Lib\\site-packages\\pandas\\core\\indexes\\base.py:3812, in Index.get_loc(self, key)
3807 if isinstance(casted_key, slice) or (
3808 isinstance(casted_key, abc.Iterable)
3809 and any(isinstance(x, slice) for x in casted_key)
3810 ):
3811 raise InvalidIndexError(key)
-> 3812 raise KeyError(key) from err
3813 except TypeError:
3814 # If we have a listlike key, _check_indexing_error will raise
3815 # InvalidIndexError. Otherwise we fall through and re-raise
3816 # the TypeError.
3817 self._check_indexing_error(key)
KeyError: ‘人気'”
}このエラーが出ました、エラーをなくすにはどうすればいいですか?
教えてください。
KeyError: ‘人気’”
ということは”人気”の列が存在していないかもしれません。
13行目と89行目の”人気”に関連する行をコメントアウトして実行してみてください。
いつも参考にさせていただいております。
「【追記 2024/1/18】複数ファイルを一度に予想する」において、以下のエラーが発生します。
(一つのファイルを予想するときはエラーは発生しません。)
pd.read_csv(ファイル, encoding=”UTF-8”)のように文字コードを指定して開くことを試みてもうまくいきません。何か心当たりございますでしょうか。
Processing feature 10/10Traceback (most recent call last):
File “predict.py”, line 17, in
new_data = pd.read_csv(‘race_data/’ + path, encoding=”UTF-8″)
File “/usr/local/lib/python3.7/site-packages/pandas/util/_decorators.py”, line 311, in wrapper
return func(*args, **kwargs)
File “/usr/local/lib/python3.7/site-packages/pandas/io/parsers/readers.py”, line 586, in read_csv
return _read(filepath_or_buffer, kwds)
File “/usr/local/lib/python3.7/site-packages/pandas/io/parsers/readers.py”, line 482, in _read
parser = TextFileReader(filepath_or_buffer, **kwds)
File “/usr/local/lib/python3.7/site-packages/pandas/io/parsers/readers.py”, line 811, in __init__
self._engine = self._make_engine(self.engine)
File “/usr/local/lib/python3.7/site-packages/pandas/io/parsers/readers.py”, line 1040, in _make_engine
return mapping[engine](self.f, **self.options) # type: ignore[call-arg]
File “/usr/local/lib/python3.7/site-packages/pandas/io/parsers/c_parser_wrapper.py”, line 69, in __init__
self._reader = parsers.TextReader(self.handles.handle, **kwds)
File “pandas/_libs/parsers.pyx”, line 542, in pandas._libs.parsers.TextReader.__cinit__
File “pandas/_libs/parsers.pyx”, line 642, in pandas._libs.parsers.TextReader._get_header
File “pandas/_libs/parsers.pyx”, line 843, in pandas._libs.parsers.TextReader._tokenize_rows
File “pandas/_libs/parsers.pyx”, line 1917, in pandas._libs.parsers.raise_parser_error
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xff in position 360: invalid start byte
そもそものファイルの文字コードは何でしょうか?
日本語があるファイルだと思うのでshift-jisを試してみるとか、ですかね?
new_data = pd.read_csv(‘race_data/’ + path, encoding=’shift_jis’)
ご返信ありがとうございます。
私はmacを利用しているため、ローカルに自動生成される「.DS_Store」を読み込もうとしてエラーになっておりました。「.DS_Store」を削除することで解決しました。
上記のrace_table_scraping.pyのコードをコピーし、実行したところ、
Error occurred while fetching data from https://db.netkeiba.com/horse/2019103588
Error occurred while fetching data from https://db.netkeiba.com/horse/2016106606
Error occurred while fetching data from https://db.netkeiba.com/horse/2018104963
Error occurred while fetching data from https://db.netkeiba.com/horse/2016104618
Error occurred while fetching data from https://db.netkeiba.com/horse/2019105219
Error occurred while fetching data from https://db.netkeiba.com/horse/2018105269
Error occurred while fetching data from https://db.netkeiba.com/horse/2019100109
Error occurred while fetching data from https://db.netkeiba.com/horse/2017105082
Error occurred while fetching data from https://db.netkeiba.com/horse/2019105346
Error occurred while fetching data from https://db.netkeiba.com/horse/2017102170
Error occurred while fetching data from https://db.netkeiba.com/horse/2018105081
Error occurred while fetching data from https://db.netkeiba.com/horse/2019104706
Error occurred while fetching data from https://db.netkeiba.com/horse/2019105056
Error occurred while fetching data from https://db.netkeiba.com/horse/2018106273
Error occurred while fetching data from https://db.netkeiba.com/horse/2016110103
Error occurred while fetching data from https://db.netkeiba.com/horse/2016100915
Error occurred while fetching data from https://db.netkeiba.com/horse/2020103626
ということになり、scvファイルは白紙になりました。どうすればいいですか?
netkeibaのサイトの方で、データ取得に制限が掛かってしまいました。
そのため、現在コードが正常に動作していない状況です。
予想するにおいて、実行したところ
Traceback (most recent call last):
File “C:\Users\こうの しょうた\Documents\卒研\race_yosou.py”, line 11, in
new_data = pd.read_csv(‘race_data/’ + file_name + ‘.csv’)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\こうの しょうた\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.11_qbz5n2kfra8p0\LocalCache\local-packages\Python311\site-packages\pandas\io\parsers\readers.py”, line 1026, in read_csv
return _read(filepath_or_buffer, kwds)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\こうの しょうた\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.11_qbz5n2kfra8p0\LocalCache\local-packages\Python311\site-packages\pandas\io\parsers\readers.py”, line 620, in _read
parser = TextFileReader(filepath_or_buffer, **kwds)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\こうの しょうた\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.11_qbz5n2kfra8p0\LocalCache\local-packages\Python311\site-packages\pandas\io\parsers\readers.py”, line 1620, in __init__
self._engine = self._make_engine(f, self.engine)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\こうの しょうた\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.11_qbz5n2kfra8p0\LocalCache\local-packages\Python311\site-packages\pandas\io\parsers\readers.py”, line 1898, in _make_engine
return mapping[engine](f, **self.options)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\こうの しょうた\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.11_qbz5n2kfra8p0\LocalCache\local-packages\Python311\site-packages\pandas\io\parsers\c_parser_wrapper.py”, line 93, in __init__
self._reader = parsers.TextReader(src, **kwds)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “parsers.pyx”, line 574, in pandas._libs.parsers.TextReader.__cinit__
File “parsers.pyx”, line 663, in pandas._libs.parsers.TextReader._get_header
File “parsers.pyx”, line 874, in pandas._libs.parsers.TextReader._tokenize_rows
File “parsers.pyx”, line 891, in pandas._libs.parsers.TextReader._check_tokenize_status
File “parsers.pyx”, line 2053, in pandas._libs.parsers.raise_parser_error
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0x94 in position 8: invalid start byte
このようなエラーが出ました。
予想したいファイル名はrace_date_nakayama_11R_20221225という名前にしています。
ファイルは文字ばけが無いようにしました。
どこを直せばいいか教えて欲しいです。
文字コードの変換エラーのようですね。
エラーメッセージだけでは確実なことは言えないのですが、
ファイルの中に日本語が含まれている、文字コードがutf-8以外になってしまっている
ことが原因なのではないかと推察します。