
これまでGoogle Colaboratory上でWhisperでも文字起こしを試してきましたが、動作が安定せず全文文字起こしすることができませんでした。
無料版だと高速なGPUへの割り当てがされづらかったり、使用上限がされていたりするため、途中で処理が止まってしまうそうです。
有料版にすれば解決しそうですが、今回はお金がかかるのでやめておきます。
そこで今回はローカルPC上でWhisperを使った文字起こしの方法をお伝えします。
PCのスペックによるとは思うのですが、Colab上で実施するよりはかなり時間がかかってしまいます。
それでも、途中で止まってしまうよりは良いですよね。
環境準備
まずは環境の準備から。
今回使用するものは以下の通り。
- VS Code
- python
- Git
早速インストールしていきます。
VS Codeのインストール
VS Codeのインストールについては下記のサイトに詳しく書いてあるので、こちらを参照してください。
VSCodeのインストール方法について解説する【初心者向き】
pythonのインストール
pythonのインストールについては下記のサイトに詳しく書いてあるので、こちらを参照してください。
Gitのインストール
Gitのインストールについては下記のサイトに詳しく書いてあるので、こちらを参照してください。
Gitをインストールしてみよう!Windows/Macどちらも丁寧に解説
文字起こし処理の実装
フォルダを作成する
適当なフォルダに「whisper」フォルダを作成してください。フォルダ名は何でも大丈夫です。
VS Codeでフォルダを開く
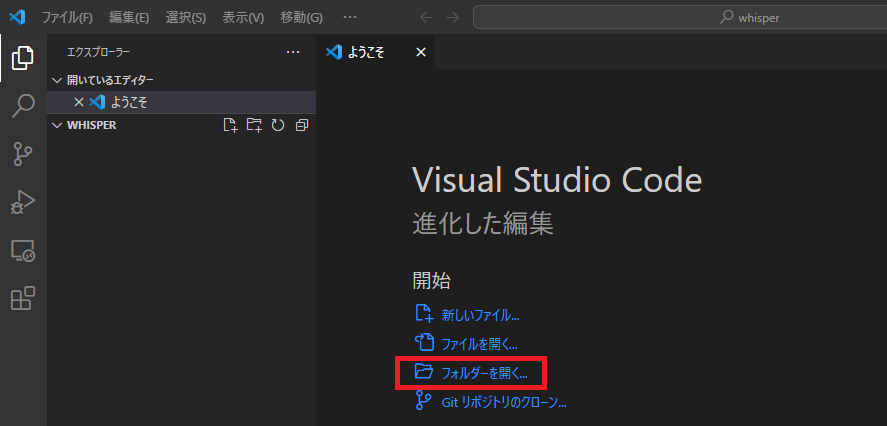
VS Codeを開くと下記のような画面になるので、「フォルダーを開く」から先ほど作成したフォルダを指定してください。
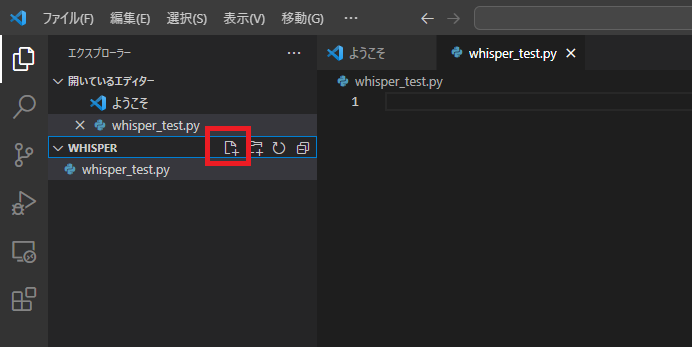
pythonファイルを作成し、コードを記述する
下記アイコンをクリックして、「whisper_test.py」ファイルを作成してください。
※whisper.pyにしてしまうとエラーが出てしまうので注意してください。
ファイルを作成したら下記コードをコピーして貼り付けてください。
「ファイル名」の部分は文字起こししたい音声ファイルの名称に変更してください。
import whisper
fileName = "ファイル名"
lang = "ja"
model = whisper.load_model("large")
# Load audio
audio = whisper.load_audio(f"content/{fileName}")
result = model.transcribe(audio, verbose=True, language=lang)
# Write into a text file
with open(f"download/{fileName}.txt", "w") as f:
f.write(f"▼ Transcription of {fileName}\n")
f.write(result["text"])ファイル格納用のフォルダを作成する
フォルダアイコンをクリックし、ファイルアップロード用のフォルダ「content」と文字起こし後のファイルの格納用のフォルダ「download」を作成する。
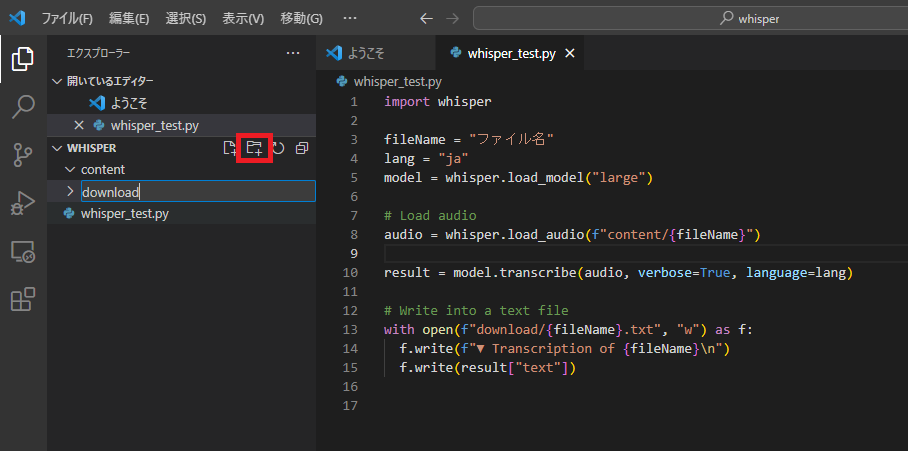
作成したcontentフォルダに文字起こし用のファイルを格納してください。
プログラムを動かしてみる
動かす前に、必要なライブラリをインストールします。
まずはターミナルを表示してください。
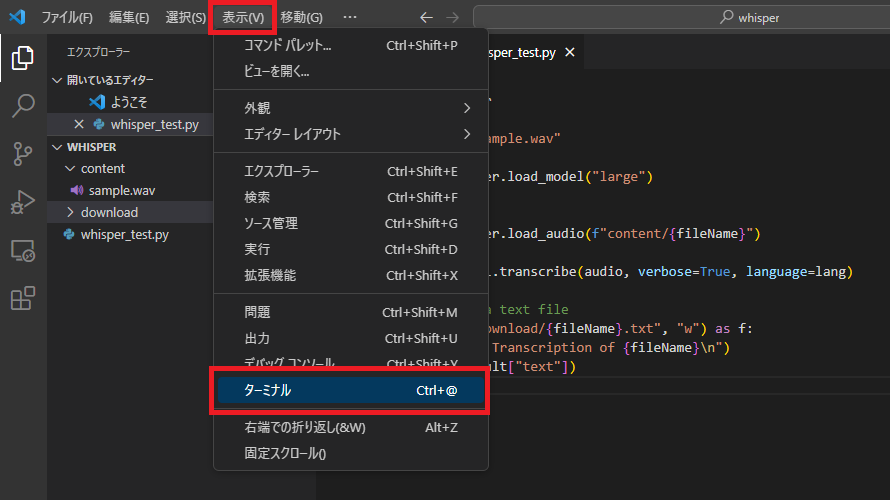
下記コマンドをターミナルに張り付け、エンターで実行してください。
pip install git+https://github.com/openai/whisper.git --userwhisperがインストールされたら、下記コマンドで実行してください。
処理のせいでPCが重くなると思いますが、我慢してくださいね!
python whisper_test.py結果
約10MBで11分ほどのファイルで試してみましたが、すべての音声の文字起こしをすることができました。
ただ、PCが重くなるのと時間は40分ほど掛かってしまいました。。。
多少動きは遅くなってしまいますが、全文書き起こせたので良かったです。
こちらの記事を参考にぜひ試してみてください。
おまけ(ChatGPTに渡せるように文字を分割する)
ChatGPTに文字起こししたテキストを渡したいと思っても、文字数が多すぎてエラーになってしまいます。ChatGPTは2500文字程度までしか受け付けないようです。
文字起こししたテキストファイルを「content」フォルダに格納し、
下記のコードを「text_split.py」というファイルを作成して貼り付けてください。
※テキストファイルは、余計な文字は削除するなり、複数テキストをまとめるなり、加工してください
# ファイルを開く
with open("content/sample.txt", "r",encoding="utf-8_sig") as file:
# ファイルの内容を読み込む
content = file.read()
# 改行する文字数を指定する
line_length = 2500
# 文字列を改行する
lines = []
while len(content) > line_length:
# 指定した文字数ごとに文字列を分割し、改行文字を追加する
lines.append(content[:line_length] + "\n\n")
content = content[line_length:]
lines.append(content)
# 新しいファイルに書き込む
with open("download/result.txt", "w") as new_file:
new_file.writelines(lines)
# ファイルを閉じる
new_file.close()python text_split.pyと入力し実行すると、2500文字ごとに改行が挿入されたテキストファイルが「download」フォルダ内に出力されます。
ぜひ試してみてください。
追記
PCマイクからのリアルタイム文字起こし
whisperを使ってPCのマイクからリアルタイムに文字起こしする方法についても実施してみました。

[WinError 2] 指定されたファイルが見つかりません。エラーについて
ffmpegのインストールで解決します。
詳細はリンクの記事やコメント欄を参照ください。
【Windows】PATHの設定なしでFFmpegをインストールする方法
コメントでご指摘いただいた方ありがとうございます!


コメント
記事作成ありがとうございます。
無事にwhisperで文字起こしを行うことができました。
1つ質問なのですがターミナル上にでてる[20:35.000 –> 20:37.000]などの時間をテキストへ保存する方法を教えていただけますでしょうか。
よろしくお願いいたします。
コメントありがとうございます。
ターミナル上に出る時間と全く同じではありませんが以下の方法で時間を表示することが出来ます。
ファイルの先頭に「import datetime」を追記し、
プログラムの最後の行をコメントアウトし、以下のように修正してみてください。
# f.write(result["text"])
for segment in result["segments"]:
start = str(datetime.timedelta(seconds=segment['start']))
end = str(datetime.timedelta(seconds=segment['end']))
f.write(start + ' --> ' + end + ' : ' + segment['text'] + '\n')
resultの中の”segments”というプロパティの中に時間や時間に対応したテキストなどが格納されています。
無事に時間を表示して保存できました。
丁寧に教えていただきありがとうございます。
今後とも応援しております。
初めまして、わかりやすい記事の作成をいただきとても参考になっております。
1点お伺いさせていただきたいのですがターミナルにてPythonを実行すると
” [WinError 2] 指定されたファイルが見つかりません。”
と表示されてしまいます。
調べてみましたがわからず、、、
もしお分かりでしたらご教示いただけますでしょうか。
よろしくお願いいたします。
コメントありがとうございます。
そのエラーの原因として以下が考えられます。
1.whisper.load_model(“large”)の”large”という部分の文字が間違っていて、存在していないモデルを指定している。
2.whisper.load_audio(f”content/{fileName}”)という部分で、contentフォルダがないか、読み込もうとしているファイルがないか。
3.with open(f”download/{fileName}.txt”, “w”) as f:という部分で、downloadフォルダが存在しない。
上記について再度確認してみてください。
横からすみません。
先日同じようなことで少し悩んだもので…。
ffmpegがパスの通ったところにありますか?
一度確認してみてください。
コメントありがとうございます。
ffmpegは音声ファイルを変換するために使用されるソフトです。
読み返してみたらffmpegは使われていないですね。。。
私の記事が間違っていました。
ご指摘ありがとうございます!
なので、” [WinError 2] 指定されたファイルが見つかりません。”というエラーはffmpegは関係ないものと考えています。
上記のポイント以外にもう一つ考えれるとしたら、Pythonを実行する際に対象の実行ファイルの階層にいるかどうかかと思います。
cdコマンドで適切な階層にいる必要があります。
記事ありがとうございます。
自分のWindow11環境で試したところsubprocess.py辺りで、指定されたファイルが見つかりません。
となりパス通してみたりとかいろいろ試しても解決しませんでした。
whisper filenotfounderrorで検索したところ下記Teratailが見つかり、アンサーにあるffmpeg「本体」をインストールすると動作するようになりました。
https://teratail.com/questions/b36fxex20hc3nx
(openai/whisper GitHubページのSetupにも、
It also requires the command-line tool ffmpeg to be installed on your systemの記載有)
ちなみに変換元のファイルにはmp3を指定しています。何かお役に立てば幸いです。
有益な情報ありがとうございます!
私も同じようなエラー「” [WinError 2] 指定されたファイルが見つかりません。”」でかなり悩みましたので、解決方法を共有します。
結果として既に書き込みがある通り、ffmpegのインストールで解決しました。
ただ私は、ffmpegのインストールも少し苦戦しまして、結果としてコマンドプロンプトから直接インストール&環境変数の変更でどうにかできました。
https://roboin.io/article/2024/02/25/install-ffmpeg-to-windows/
その後、VSCodeを再起動して、スクリプトを実行してから、ターミナルでコマンド実行で動き出しました。ご参考になりましたら
有益なコメントありがとうございます。
記事内に追記させていただきます。
初めまして,とても分かりやすい記事で読みやすかったです.
コメントを送らせていただいたのはwhisper_test.pyを実行したときに[WinError 126] 指定されたモジュールが見つかりませんというエラーが出たため,その解決方法をご教授いただきたいからです.この記事通りに進めたつもりではあるのですがそのエラーの解決策がわかりませんでした.何卒よろしくお願いします.
本記事のコメント欄をお読みいただけますでしょうか?
他の読者さんが同様のエラーの解決方法を記載してくれています。
よろしくお願いします。
(恐らく)whisperの対応バージョンが3.8から3.10であるため、現行の最新のPython(3.12.4(2024/10/04現在))をインストールした場合これが原因のエラーに当たる可能性が高いです。