
こちらの記事は旧AI開発の記事になっております。netkeibaの対策により現在はスクレイピングが禁止されております。
新しい競馬AIの記事はこちらからになります!ぜひ読んでみてください。

このモデル作成の記事の続きになります。

モデルが生成出来たらそのモデルを使って予想した場合の回収率って気になりますよね!
前回の記事ではaucや的中率などは分かりましたが、掛け金がいくらになるかまでは計算していませんでした。
今回はモデルを使って掛けた場合にいくらになるのか、単勝回収率と複勝回収率を計算するプログラムを作成していきます。
払い戻し情報を取得する
回収率を計算するには払い戻し情報が必要になってきます。
毎度のことnetkeibaから取得していきます。
画像は宝塚記念の払い戻し情報です。
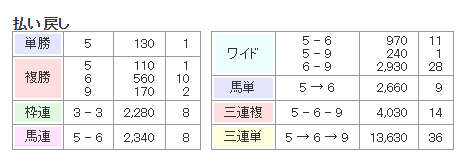
ここからスクレイピングで情報を引っこ抜いていきます。
スクレイピングのコード
以下がスクレイピングするコードです。
ベースは競馬記事①のスクレイピングコードと同じです。
レース結果は取得せずに、払い戻しだけを取得するように書き換えています。
前回からの変更点としては、2回連続で存在しないURLにアクセスした場合にその開催日をスキップするようにしました。(55-58行目あたり)
import requests
from bs4 import BeautifulSoup
import time
def appendPayBack1(varSoup):#複勝とワイド以外で使用
varList = []
varList.append(varSoup.contents[3].contents[0])
varList.append(varSoup.contents[5].contents[0])
payBackInfo.append(varList)
def appendPayBack2(varSoup):#複勝とワイドで使用
varList = []
for var in range(3):
try:#複勝が3個ないときを除く
varList.append(varSoup.contents[3].contents[2*var])
except IndexError:
pass
try:
varList.append(varSoup.contents[5].contents[2*var])
except IndexError:
pass
payBackInfo.append(varList)
#払い戻しの情報
for year in range(2020, 2023):
List=[]
l=["01","02","03","04","05","06","07","08","09","10"]#競馬場
for w in range(len(l)):
for z in range(7):#開催、6まで十分だけど保険で7
continueCounter = 0 # 'continue'が実行された回数をカウントするためのカウンターを追加
for y in range(13):#日、12まで十分だけど保険で14
if y<9:
url1="https://db.netkeiba.com/race/"+str(year)+l[w]+"0"+str(z+1)+"0"+str(y+1)
else:
url1="https://db.netkeiba.com/race/"+str(year)+l[w]+"0"+str(z+1)+str(y+1)
yBreakCounter = 0#yの更新をbreakするためのカウンター
for x in range(12):#レース12
if x<9:
url=url1+str("0")+str(x+1)
else:
url=url1+str(x+1)
try:
r=requests.get(url)
except requests.exceptions.RequestException as e:
print(f"Error: {e}")
print("Retrying in 10 seconds...")
time.sleep(10) # 10秒待機
r=requests.get(url)
soup = BeautifulSoup(r.content.decode("euc-jp", "ignore"), "html.parser")#バグ対策でdecode
soup_span = soup.find_all("span")
allnum=(len(soup_span)-6)/3#馬の数
if allnum < 1:#urlにデータがあるか判定
yBreakCounter+=1
print('continue: ' + url)
continueCounter += 1 # 'continue'が実行された回数をカウントアップ
if continueCounter == 2: # 'continue'が2回連続で実行されたらループを抜ける
continueCounter = 0
break
continue
else:
continueCounter = 0 # 'continue'が実行されなかったらカウントをリセット
allnum=int(allnum)
payBack = soup.find_all("table",summary='払い戻し')
payBackInfo=[]#単勝、複勝、枠連、馬連、ワイド、馬単、三連複、三連単の順番で格納
appendPayBack1(payBack[0].contents[1])#単勝
try:
payBack[0].contents[5]#これがエラーの時複勝が存在しない
appendPayBack2(payBack[0].contents[3])#複勝
try:
appendPayBack1(payBack[0].contents[7])#馬連
except IndexError:
appendPayBack1(payBack[0].contents[5])#通常は枠連だけど、この時は馬連
except IndexError:#この時複勝が存在しない
payBackInfo.append([payBack[0].contents[1].contents[3].contents[0],'110'])#複勝110円で代用
print("複勝なし")
appendPayBack1(payBack[0].contents[3])#馬連
appendPayBack2(payBack[1].contents[1])#ワイド
appendPayBack1(payBack[1].contents[3])#馬単
appendPayBack1(payBack[1].contents[5])#三連複
try:
appendPayBack1(payBack[1].contents[7])#三連単
except IndexError:
appendPayBack1(payBack[1].contents[5])#三連複を三連単の代わり
race_id = url.rsplit('/', 1)[-1]
List.append([race_id,payBackInfo])
soup_smalltxt = soup.find_all("p",class_="smalltxt")
detail=str(soup_smalltxt).split(">")[1].split(" ")[1]
print(detail+str(x+1)+"R")#進捗を表示
import csv
with open('payback/'+str(year)+'.csv', 'w', newline='',encoding="SHIFT-JIS") as f:
csv.writer(f).writerows(List)
print("終了")注意!
24行目で取得する年数を設定することが出来ます。
この処理はかなり時間がかかるので、数年ごとに分けて実行したほうが良いと思います。
一番最初は1年分で競馬場を1か所、開催の条件を1、日にちの条件も1にして実行して中身を確認してください。
実行
※実行前に「payback」フォルダの作成をお忘れなく!
実行するには以下のコマンドをターミナルで打ち込んでください。
python scraping_payback.py実行すると「payback」フォルダにYYYY.csvというファイルが年数分作成されているはずです。
データの確認
中身を確認すると以下のようになっていれば成功です。
202210040812,"[['15', '430'], ['15', '180', '10', '160', '3', '450'], ['10 - 15', '1,150'], ['10 - 15', '490', '3 - 15', '1,940', '3 - 10', '1,470'], ['15 → 10', '2,010'], ['3 - 10 - 15', '7,020'], ['15 → 10 → 3', '27,550']]"データの構成としては、”race_id,払い戻し情報”となっています。
払い戻し情報は単勝、複勝、馬連、ワイド、馬単、三連複、3連単という順番になっています。
今回は単勝、複勝しか使いませんが、念のため取得しています。
まとめ
払い戻し情報の取得はできましたでしょうか?
かなり時間のかかるコードのため、今回はここまでとしておきます。
次回は取得した払い戻し情報を使って、実際に回収率を計算していきます。
次の記事をお待ちください!


コメント
お世話になっております
コードをコピーして実行したところurlは順次ターミナルに表示されるのですが,csvの中身を見ても空白で何のデータも得れていないようです
当方,プログラミングに関しては全くの初心者で解決策など全く分かりません
お忙しとは存じますが,ご教授いただけますと幸いです.
netkeibaの方でクローラー対策が行われたそうです。
アクセス頻度が高いと引っかかってしまうそうです。
私もダメになりました。
Seleniumという技術を使うと回避が出来ます。
以下サンプルコードです。適切な箇所に設定してみてください。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
# WebDriverの設定
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get(url)
soup = BeautifulSoup(driver.page_source, ‘html.parser’)
これより以下は同じコードで動きます。
私も上の方と同じで空のcsvだけが保存されます。Seleniumを使っても同じ結果になります。Chrome の画面が開いてるのは確認できるのですが、払い戻し画面は開いてないようにみえます。払い戻し画面が開かないと情報は取得できないのでしょうか?
払い戻しの画面が開いていないのであればデータは取得できません。
詳細な事象まで分からないので、生成AI等にソースコードを渡し、修正点を確認してみてください。