
今回はWhisperを使って、パソコンのマイクから拾った言葉をリアルタイムで文字起こしする方法について紹介します。
リアルタイムで文字起こしすることができれば、会議中にメモが不要になりディスカッションに集中できるようになりますし、その場で議事録に書き起こすこともできます。
前回はWeb会議の録画ファイルからの文字起こしもやっていますので、そちらの記事も参照してみてください。

環境準備
まずは環境の準備から。
今回使用するものは以下の通り。
- VS Code
- python
- Git
早速インストールしていきます。
VS Codeのインストール
VS Codeのインストールについては下記のサイトに詳しく書いてあるので、こちらを参照してください。
VSCodeのインストール方法について解説する【初心者向き】
pythonのインストール
pythonのインストールについては下記のサイトに詳しく書いてあるので、こちらを参照してください。
Gitのインストール
Gitのインストールについては下記のサイトに詳しく書いてあるので、こちらを参照してください。
Gitをインストールしてみよう!Windows/Macどちらも丁寧に解説
whisper_micのインストール
whisper_micの前提ソフトウェアのインストール
コマンドプロンプトを管理者として開き、次のコマンドを実行。
pip install -U SpeechRecognition numpy tqdm more-itertools transformers ffmpeg-python click pyaudio pydub
whisper_mic のダウンロード
任意のフォルダで次のコマンドを実行する。
git clone https://github.com/mallorbc/whisper_mic
ダウンロードが完了したら指定したパスにwhisper_micが作成されています。
再度インストールしなおす場合は以下のコマンドでフォルダごと削除できます。
rmdir /s /q whisper_mic
ダウンロードしたwhisper_micを編集する
先ほどダウンロードしたwhisper_micのフォルダをVS Codeで開いてください。
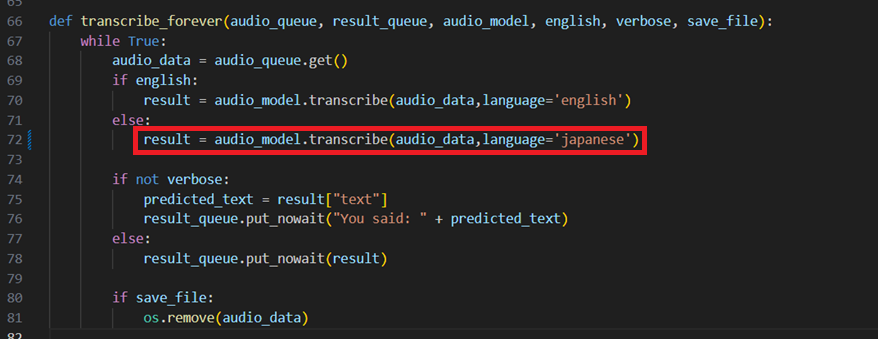
cli.pyの72行目を以下の画像のように修正してください。
日本語の言葉の認識ができるようになります。
,language='japanese'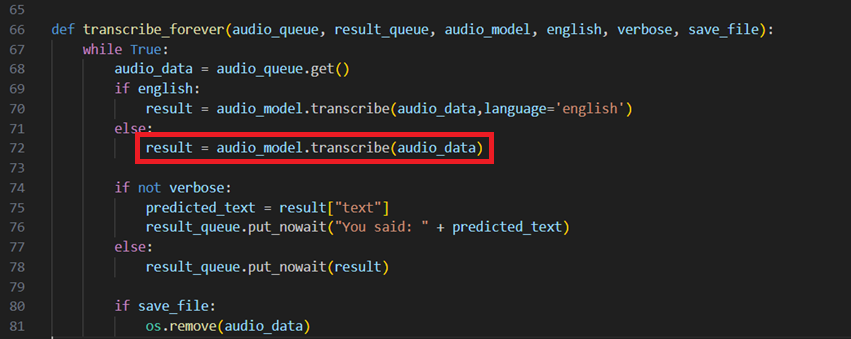
実行してマイクに話しかける
VS Codeのターミナルで以下のコードを入力し、プログラムを実行します。
python cli.py --model smallメモリに余裕がある場合は「model medium」や「model large」を試してみてください。より高い精度で文字起こしができます。
実行時にもし以下のようなエラーが出た場合はwhisperの再インストールをします。
No module named ‘whisper’
argument of type ‘NoneType’ is not iterable
pip uninstall whisper
pip install openai-whispermodel smallで実行する
音声認識させた結果は以下の通りです。
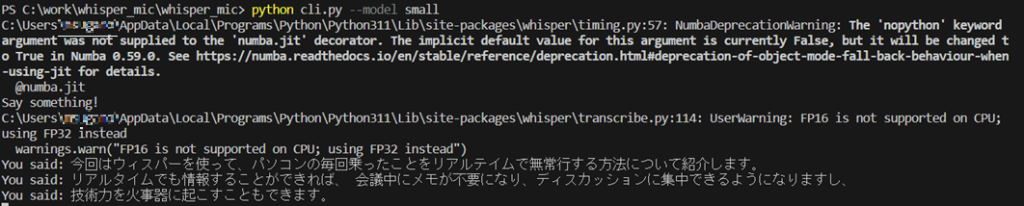
マイクでの言葉の認識はしっかりできていますが、smallでは少し精度が低いですね。滑舌の問題もあるかもしれませんが。
model mediumで実行する
次はmodel mediumで実行してみます。
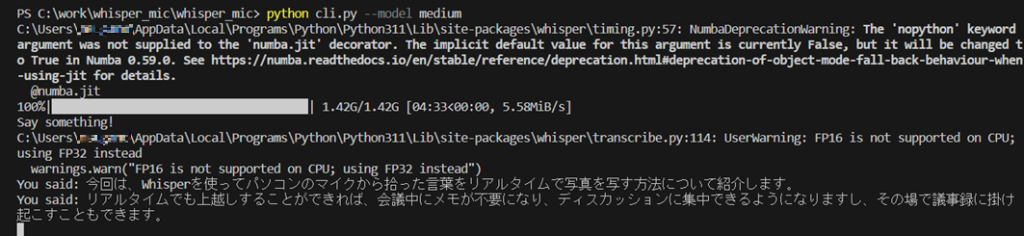
mediumにするとかなり良い精度で文字起こしができています。少し噛んでしまった部分があったのですが、文脈を読んで修正されています!すごい!!
(whisperを使ってマイクの、パソコンのマイクから拾った、、、と言ってしまったが消えている)
この精度で文字起こしができていれば十分使い物になりそうですね。
ちなみに私のPCではmediumまでが限界みたいでlargeは試せていません。。
結果
model largeは試せなかったのですが、model mediumの時点で良い精度で文字起こしができているのでlargeの精度は期待できそうです。
さらに文字起こしした文章をファイルに出力したりできると使い勝手がさらに良くなりそうです。
しかし難点としてPCのメモリをかなり占有してしまいます。実行するとPCがずっとうなっている状態になります。(メモリは16GB)
実際に使う場合はかなり良いスペックのPCを使用する必要がありそうなので、全員が簡単に使うという状態になるまでにはもう少しかかりそうです。
whisperで文字起こし→ChatGPTで議事録をリアルタイムで作成し、タスクや課題などをその場で可視化する未来はすぐ訪れそうですね。
ぜひ試してみてください。


コメント