
こちらの記事は旧AI開発の記事になっております。netkeibaの対策により現在はスクレイピングが禁止されております。
新しい競馬AIの記事はこちらからになります!ぜひ読んでみてください。

前回からの続きの記事になります。

前回は回収率を計算するための材料として、スクレイピングを使って払い戻し情報を取得しました。
今回はその払い戻し情報を使って、回収率を計算するプログラムを組んでいきます。
回収率を計算するコード
以下のコードを第3回目で作成したモデルに組み込んでください。
差し込む場所は、モデルを保存した後なので、上のリンクで見ていただきたいですが、82行目付近となります。
#単勝回収率、複勝回収率の計算
import ast
# 年度のリストを生成
years = range(2005, 2023)
# 各年度のCSVファイルを読み込み、一つのデータフレームに結合
df = []
for year in years:
path = f"../payback/{year}.csv"
data = pd.read_csv(path, encoding="SHIFT-JIS", header=None)
df.append(data)
betting_data = pd.concat(df, ignore_index=True)
threshold = 0.5
# 予測結果を元に賭ける馬を決定
betting_horses = {(test.iloc[i]['race_id'], test.iloc[i]['馬番']): y_pred[i] for i in range(len(y_pred)) if y_pred[i] >= threshold}
# betting_dataのレースIDをインデックスとして設定
betting_data.set_index(betting_data.iloc[:, 0].astype(str).str.strip(), inplace=True)
# 単勝と複勝の回収金額を計算
win_return_amount = 0 # 単勝の回収金額
place_return_amount = 0 # 複勝の回収金額
for (race_id, horse_number) in betting_horses:
race_id = str(int(float(race_id)))
horse_number = str(int(float(horse_number))) # 馬番を文字列に変換
race = int(race_id[-2:])
if race_id in betting_data.index:
race_data = betting_data.loc[race_id] # 対応するレースのデータを取得
race_data_list = ast.literal_eval(race_data[1])
win_data = race_data_list[0] # 単勝のデータを取得
place_data = race_data_list[1] # 複勝のデータを取得
for j in range(0, len(win_data), 2):
if win_data[j] == horse_number: # 賭けた馬が単勝した場合
win_return_amount += int(win_data[j + 1].replace(',', '')) # 回収金額を加算
for j in range(0, len(place_data), 2):
if place_data[j] == horse_number: # 賭けた馬が複勝した場合
place_return_amount += int(place_data[j + 1].replace(',', '')) # 回収金額を加算
else:
print(f"Race ID {race_id} not found in betting data.")
# 単勝と複勝の回収率を計算
betting_amount = len(betting_horses) # 賭けた回数
win_return_rate = win_return_amount / betting_amount # 単勝の回収率
place_return_rate = place_return_amount / betting_amount # 複勝の回収率
print("単勝回収率:", win_return_rate)
print("複勝回収率:", place_return_rate)実行結果
実行すると回収率がターミナル上に表示されます。
今回のモデルではAIの予測値が0.5を超えた馬にかけた場合で、正解率や回収率を算出しています。
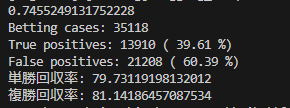
予測結果が0.5を超えた馬が35,118頭で、そのうち13,910頭が3着以内だったことがわかります。(約40%の正解率)
1番人気に掛け続けた場合は約32%当たると言われているので、それよりは高い結果ですが、
単勝回収率:79%
複勝回収率:81%
なのでまだまだ改良していかなければならないということがわかりました。
まとめ
今回回収率の計算を行ったことで、AUC(0.7455と書いてある数値)だけではなく、回収率というわかりやすい基準が出来たことで、よりモデルの精度が把握しやくなりました。
競馬は回収率が大事ですので、AUCの数値に惑わされず、回収率が高くなるようなモデルの作成を頑張ってみてください。
回収率を上げるためにやること
最後に、私もまだまだ改良中ですが、回収率を上げるためにやっていることを紹介します。
データのクレンジング
データに欠損値が多く含まれている場合に精度が落ちることがあります。なので予測に不要なデータを削除したりします。
例えば、着順が降着・中断・除外となっているデータをそのまま使ってしまっていたので削除するようにしました。
もともとは私がスクレイピングの際に、着順を正しく取得しないでテーブルの順番に番号を振ってしまっていたのが原因なのですが。(中断・除外はテーブルの一番最後に来るので、最下位の順位をつけてしまっていた)
削除した方法としては、走破時間が空のレコードの削除です。いくら着順が振られていても走っていないので走破時間は入っていません。
削除イメージ
# NaNが含まれる行を削除
df_combined = df_combined.dropna(subset=['走破時間'])他にも不要なデータを探して削除、整形してみてください。
特徴量エンジニアリング
難しい言葉を使いましたが、簡単に言うと既存の特徴量を組み合わせて新たな特徴量を作り出していくことです。
例えば以下のように新たな特徴量を作っています。
平均スピード:走破時間1/距離1の計算を5までやってから平均値を出す
平均オッズ:オッズ1~オッズ5の平均値を出す
平均着順:着順1~着順5の平均値を出す
このように特徴量を増やしていくことで、モデルの精度を高めていくことが出来ます。
特徴量の重要度を確認しながら、試してみてください!
回収率を上げていくために、LightGBMを学んでみてはいかがでしょうか!



コメント
お世話になっております。
BettingCasesはどうやって出しますか?
今回の場合betting_horses=BettingCasesと考えていいと思います。
あとAIの予測値が0.5を超えた馬にかけた場合での正解率の出し方も教えてください。
お忙しいところ大変申し訳ございません。
競馬AI③の65行目に書いてある以下が正解率になります。
print(“True positives:”, TP_count, “(“, “{:.2f}”.format(accuracy_TP), “%)”)
データクレンジングの走破時間が空のレコードを削除するコードはどこに入れればよいですか?
encode.pyの以下のコードの後あたりに入れてみてください。35行目くらい。
# DataFrameの結合
df_combined = pd.concat(df, ignore_index=True)
単勝と複勝以外の賭け方の回収率を出したいのですがどのようにコードを書き直せばよろしいですか?
単複以外はどう賭けるか次第になってくるので一概には言えないですし、実装は難しいです。
予測上位2頭・3頭で馬連、3連複の回収率を算出するのであれば、取得した3頭がレース結果と一致するのかを単複と同じようにチェックし配当を取得すれば良いです。
上位5頭で全組み合わせを掛けるとしたら、その組み合わせを作成し、レース結果とすべて照らし合わせないといけないです。
そのまま使えるかわかりませんが、私の方で仮で作成したコードを載せますので、参考にしてみてください。
※動くかわからないので、ご自身でチェックしてください。
# # 予測値をtestデータフレームに追加
test = test.assign(予測値=pd.Series(y_pred, index=test.index))
# 予測値が閾値を超える馬のデータをフィルタリング
high_pred_horses = test[y_pred >= threshold]
# レースIDごとに馬の数をカウント
race_counts = high_pred_horses.groupby(‘race_id’).size()
# 2頭以上の馬が存在するレースIDを取得
races_with_multiple_high_predictions = race_counts[race_counts >= 2].index.unique()
print(‘Betting cases(3連複): ‘, len(races_with_multiple_high_predictions))
# 3連複を購入した場合の回収率を計算
trifecta_return_amount = 0
trifecta_betting_amount = 0
# 3連複の正解数をカウント
correct_trifecta_count = 0
# 馬連を購入した場合の回収率を計算
exacta_return_amount = 0
exacta_betting_amount = 0
# 馬連の正解数をカウント
correct_exacta_count = 0
for race_id in races_with_multiple_high_predictions:
race_data = test[test[‘race_id’] == race_id]
sorted_race_data = race_data.sort_values(by=’予測値’, ascending=False)
# 上位5頭の馬から3頭を選ぶ全ての組み合わせを作成
top3_horses = sorted_race_data.iloc[:3][‘馬番’].tolist()
# 3頭の馬の組み合わせは1つしか存在しないので、直接リストに入れる
trifecta_combination = [tuple(top3_horses)]
# 上位2頭の馬を取得
top2_horses = sorted_race_data.iloc[:2][‘馬番’].tolist()
# 2頭の馬の組み合わせは1つしか存在しないので、直接リストに入れる
exacta_combination = [tuple(top2_horses)]
if str(int(float(race_id))) in betting_data.index:
race_betting_data = betting_data.loc[str(int(float(race_id)))]
trifecta_results = ast.literal_eval(race_betting_data[1])[5]
exacta_results = ast.literal_eval(race_betting_data[1])[2]
for trifecta_result, return_amount in zip(trifecta_results[::2], trifecta_results[1::2]):
trifecta_horses = sorted([int(h) for h in trifecta_result.split(‘ – ‘)])
if tuple(trifecta_horses) in trifecta_combination:
trifecta_return_amount += int(return_amount.replace(‘,’, ”))
trifecta_betting_amount += 100
correct_trifecta_count += 1
for exacta_result, return_amount in zip(exacta_results[::2], exacta_results[1::2]):
exacta_horses = sorted([int(h) for h in exacta_result.split(‘ – ‘)])
if tuple(exacta_horses) in exacta_combination:
exacta_return_amount += int(return_amount.replace(‘,’, ”))
exacta_betting_amount += 100
correct_exacta_count += 1
# 3連複の正解率を計算
trifecta_accuracy = correct_trifecta_count / len(races_with_multiple_high_predictions) * 100
print(“3連複正解率:”, round(trifecta_accuracy, 3), “%”)
trifecta_return_rate = trifecta_return_amount / trifecta_betting_amount if trifecta_betting_amount != 0 else 0
print(“3連複回収率 (上位3頭):”, round(trifecta_return_rate,3))
# 馬連の正解率を計算
exacta_accuracy = correct_exacta_count / len(races_with_multiple_high_predictions) * 100
print(“馬連正解率:”, round(exacta_accuracy, 3), “%”)
exacta_return_rate = exacta_return_amount / exacta_betting_amount if exacta_betting_amount != 0 else 0
print(“馬連回収率 (上位2頭):”, round(exacta_return_rate,3))
お忙しいところ申し訳ございません。
FileNotFoundError: [Errno 2] No such file or directory: ‘../payback/2019.csv’
というエラーが出ました。でもフォルダ名とファイル名は間違ってません
どうしてエラーがでるのでしょうか?
下記のコードの何処か変えればいいのでしょうか?
# 年度のリストを生成
years = range(2019, 2023)
# 各年度のCSVファイルを読み込み、一つのデータフレームに結合
df = []
for year in years:
path = f”../payback/{year}.csv”
data = pd.read_csv(path, encoding=”SHIFT-JIS”, header=None)
df.append(data)
教えて下さい。
宜しくお願い致します。
フォルダ名とファイル名が間違っていないのであれば、
ディレクトリ階層の問題ではないでしょうか?
「../」の意味は、一つ上の階層となるので、以下のような構成になっていないと見つけられません。
-payback
|_2019.csv
-folder
|_estimation.py
回答ありがとうございます。
「./」にしたら実行しましたが、それでも大丈夫でしょうか?
正常に動作していれば問題ございません。